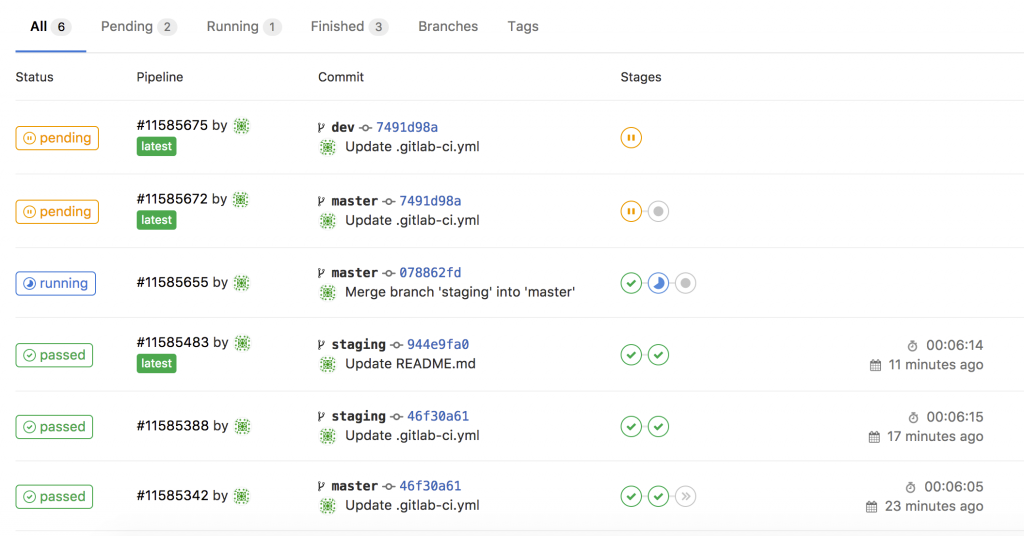
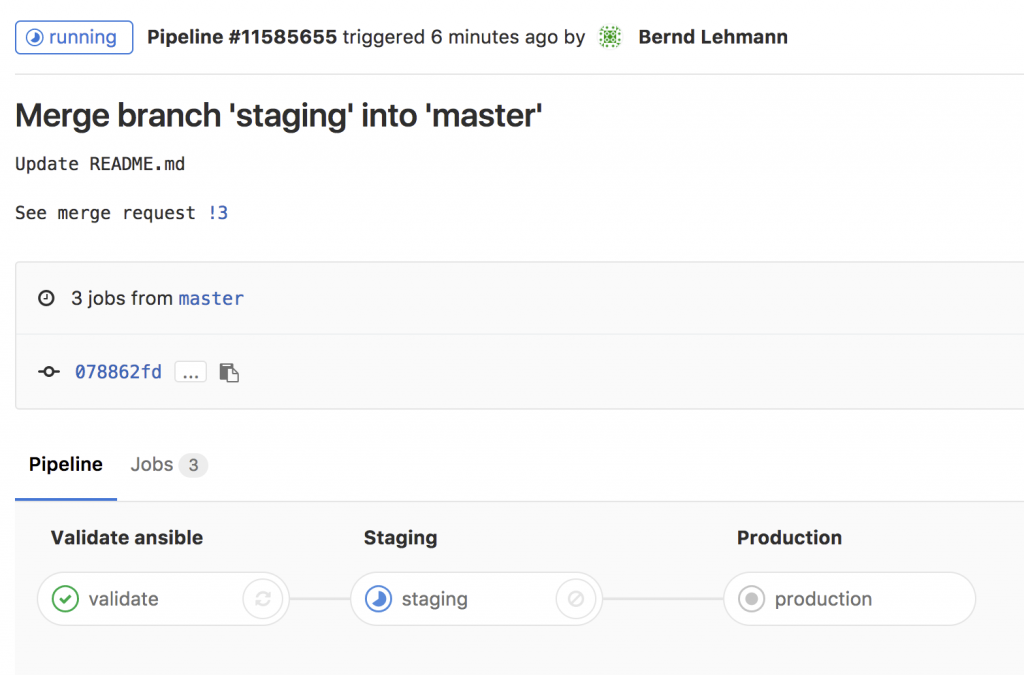
Here some interesting things I did with on-demand network simulation of Cisco IOSv and IOS XE using Vagrant. Yes, Cisco has is own product for network simulation called Cisco VIRL (Cisco Virtual Internet Routing Lab) but this is not as flexible and on-demand like using Vagrant and KVM. One of the reason was to do some continuous integration testing, same what I did with Cumulus Linux: Continuous Integration and Delivery for Networking with Cumulus Linux
You need to have an active Cisco VIRL subscription to download the VMDK images or buy the Cisco CSR1000V to get access to the ISO on the Cisco website!
IOS XE was the easiest because I found a Github repository to convert an existing CSR1000V ISO to vbox image to use with Vagrant. The only thing I needed to do was to converting the vbox image to KVM using vagrant mutate.
berndonline@lab:~/cisco-lab-vagrant$ vagrant status
Current machine states:
rtr-1 not created (libvirt)
rtr-2 not created (libvirt)
berndonline@lab:~/cisco-lab-vagrant$ vagrant up
Bringing machine 'rtr-1' up with 'libvirt' provider...
Bringing machine 'rtr-2' up with 'libvirt' provider...
==> rtr-1: Creating image (snapshot of base box volume).
==> rtr-2: Creating image (snapshot of base box volume).
==> rtr-1: Creating domain with the following settings...
==> rtr-1: -- Name: cisco-lab-vagrant_rtr-1
==> rtr-2: Creating domain with the following settings...
==> rtr-1: -- Domain type: kvm
==> rtr-2: -- Name: cisco-lab-vagrant_rtr-2
==> rtr-1: -- Cpus: 1
==> rtr-2: -- Domain type: kvm
==> rtr-1: -- Feature: acpi
==> rtr-2: -- Cpus: 1
==> rtr-2: -- Feature: acpi
==> rtr-2: -- Feature: apic
==> rtr-1: -- Feature: apic
==> rtr-2: -- Feature: pae
==> rtr-1: -- Feature: pae
==> rtr-2: -- Memory: 2048M
==> rtr-2: -- Management MAC:
==> rtr-2: -- Loader:
==> rtr-1: -- Memory: 2048M
==> rtr-2: -- Base box: iosxe
....
==> rtr-1: Waiting for SSH to become available...
==> rtr-2: Waiting for SSH to become available...
==> rtr-1: Configuring and enabling network interfaces...
==> rtr-2: Configuring and enabling network interfaces...
rtr-1: SSH address: 10.255.1.84:22
rtr-1: SSH username: vagrant
rtr-1: SSH auth method: private key
rtr-2: SSH address: 10.255.1.208:22
rtr-2: SSH username: vagrant
rtr-2: SSH auth method: private key
==> rtr-1: Running provisioner: ansible...
rtr-1: Running ansible-playbook...
PLAY [all] *********************************************************************
TASK [run show version on remote devices] **************************************
==> rtr-2: Running provisioner: ansible...
rtr-2: Running ansible-playbook...
PLAY [all] *********************************************************************
TASK [run show version on remote devices] **************************************
ok: [rtr-1]
PLAY RECAP *********************************************************************
rtr-1 : ok=1 changed=0 unreachable=0 failed=0
ok: [rtr-2]
PLAY RECAP *********************************************************************
rtr-2 : ok=1 changed=0 unreachable=0 failed=0
berndonline@lab:~/cisco-lab-vagrant$ vagrant status
Current machine states:
rtr-1 running (libvirt)
rtr-2 running (libvirt)
berndonline@lab:~/cisco-lab-vagrant$
Afterwards you can connect with vagrant ssh to your virtual IOS XE VM:
berndonline@lab:~/cisco-lab-vagrant$ vagrant ssh rtr-1
csr1kv#show version
Cisco IOS XE Software, Version 03.16.00.S - Extended Support Release
Cisco IOS Software, CSR1000V Software (X86_64_LINUX_IOSD-UNIVERSALK9-M), Version 15.5(3)S, RELEASE SOFTWARE (fc6)
Technical Support: http://www.cisco.com/techsupport
Copyright (c) 1986-2015 by Cisco Systems, Inc.
Compiled Sun 26-Jul-15 20:16 by mcpre
Cisco IOS-XE software, Copyright (c) 2005-2015 by cisco Systems, Inc.
All rights reserved. Certain components of Cisco IOS-XE software are
licensed under the GNU General Public License ("GPL") Version 2.0. The
software code licensed under GPL Version 2.0 is free software that comes
with ABSOLUTELY NO WARRANTY. You can redistribute and/or modify such
GPL code under the terms of GPL Version 2.0. For more details, see the
documentation or "License Notice" file accompanying the IOS-XE software,
or the applicable URL provided on the flyer accompanying the IOS-XE
software.
ROM: IOS-XE ROMMON
csr1kv uptime is 9 minutes
Uptime for this control processor is 10 minutes
System returned to ROM by reload
System image file is "bootflash:packages.conf"
Last reload reason:
....
berndonline@lab:~/cisco-lab-vagrant$ vagrant destroy
==> rtr-2: Removing domain...
==> rtr-1: Removing domain...
berndonline@lab:~/cisco-lab-vagrant$
Running IOSv on KVM wasn’t that easy because you only get VMDK (Virtual Machine Disk) which you need to convert to a QCOW2 image. The next step is to boot the QCOW2 image and add some additional configuration changes before you can use this with Vagrant. Give the VM at least 2048 MB and min. 1 vCPU.
Ones the VM is booted, connect and add the following configuration below. You need to create an vagrant user and add the ssh key from Vagrant, additionally create an EEM applet to generate the rsa key during boot otherwise Vagrant cannot connect to the VM. Afterwards save the running-config and turn off the VM:
conf t
ip vrf vrf-mgmt
rd 1:1
exit
interface Gig0/0
description management
ip vrf forwarding vrf-mgmt
ip address dhcp
no shutdown
exit
ip domain-name lab.local
aaa new-model
aaa authentication login default local
aaa authorization exec default local
username vagrant privilege 15 secret vagrant
crypto key generate rsa general-keys modulus 2048
ip ssh version 2
ip ssh authentication-retries 5
ip ssh pubkey-chain
username vagrant
key-hash ssh-rsa DD3BB82E850406E9ABFFA80AC0046ED6
exit
exit
line vty 0 4
exec-timeout 0 0
transport input ssh
exit
shell processing full
event manager session cli username vagrant
event manager applet EEM_SSH_Keygen authorization bypass
event syslog pattern SYS-5-RESTART
action 0.0 info type routername
action 0.1 set status none
action 1.0 cli command enable
action 2.0 cli command "show ip ssh | include ^SSH"
action 2.1 regexp "([ED][^ ]+)" \$_cli_result result status
action 2.2 syslog priority informational msg "SSH is currently \$status"
action 3.0 if \$status eq Disabled
action 3.1 cli command "configure terminal"
action 3.2 cli command "crypto key generate rsa usage-keys label SSHKEYS modulus 2048"
action 3.3 cli command "end"
action 3.4 cli command "copy run start"
action 3.5 syslog priority informational msg "SSH keys generated by EEM"
action 4.0 end
end
exit
write mem
Now the QCOW2 image is ready to use with Vagrant. Create an instance folder under the user vagrant directory and copy the QCOW2 image. As well create an metadata.json file:
mkdir -p ~/.vagrant.d/boxes/iosv/0/libvirt/
cp IOSv.qcow2 ~/.vagrant.d/boxes/iosv/0/libvirt/box.img
printf '{"provider":"libvirt","format":"qcow2","virtual_size":2}' > metadata.json
The IOSv image is ready to use with Vagrant, just create an Vagrantfile with the needed configuration and boot up the VMs.
berndonline@lab:~/cisco-lab-vagrant$ vagrant status
Current machine states:
rtr-1 not created (libvirt)
rtr-2 not created (libvirt)
berndonline@lab:~/cisco-lab-vagrant$ vagrant up
Bringing machine 'rtr-1' up with 'libvirt' provider...
Bringing machine 'rtr-2' up with 'libvirt' provider...
==> rtr-2: Creating image (snapshot of base box volume).
==> rtr-1: Creating image (snapshot of base box volume).
==> rtr-2: Creating domain with the following settings...
==> rtr-1: Creating domain with the following settings...
==> rtr-2: -- Name: cisco-lab-vagrant_rtr-2
==> rtr-2: -- Domain type: kvm
==> rtr-1: -- Name: cisco-lab-vagrant_rtr-1
==> rtr-2: -- Cpus: 1
==> rtr-1: -- Domain type: kvm
==> rtr-2: -- Feature: acpi
==> rtr-1: -- Cpus: 1
==> rtr-2: -- Feature: apic
==> rtr-1: -- Feature: acpi
==> rtr-2: -- Feature: pae
==> rtr-1: -- Feature: apic
==> rtr-2: -- Memory: 2048M
==> rtr-1: -- Feature: pae
==> rtr-2: -- Management MAC:
==> rtr-1: -- Memory: 2048M
==> rtr-2: -- Loader:
==> rtr-1: -- Management MAC:
==> rtr-2: -- Base box: iosv
==> rtr-1: -- Loader:
==> rtr-1: -- Base box: iosv
....
==> rtr-2: Waiting for SSH to become available...
==> rtr-1: Waiting for SSH to become available...
==> rtr-2: Configuring and enabling network interfaces...
==> rtr-1: Configuring and enabling network interfaces...
rtr-2: SSH address: 10.255.1.234:22
rtr-2: SSH username: vagrant
rtr-2: SSH auth method: private key
rtr-1: SSH address: 10.255.1.237:22
rtr-1: SSH username: vagrant
rtr-1: SSH auth method: private key
==> rtr-2: Running provisioner: ansible...
rtr-2: Running ansible-playbook...
PLAY [all] *********************************************************************
TASK [run show version on remote devices] **************************************
Thursday 26 October 2017 18:21:22 +0200 (0:00:00.015) 0:00:00.015 ******
==> rtr-1: Running provisioner: ansible...
rtr-1: Running ansible-playbook...
PLAY [all] *********************************************************************
TASK [run show version on remote devices] **************************************
Thursday 26 October 2017 18:21:23 +0200 (0:00:00.014) 0:00:00.014 ******
ok: [rtr-2]
PLAY RECAP *********************************************************************
rtr-2 : ok=1 changed=0 unreachable=0 failed=0
Thursday 26 October 2017 18:21:24 +0200 (0:00:01.373) 0:00:01.388 ******
===============================================================================
run show version on remote devices -------------------------------------- 1.37s
ok: [rtr-1]
PLAY RECAP *********************************************************************
rtr-1 : ok=1 changed=0 unreachable=0 failed=0
Thursday 26 October 2017 18:21:24 +0200 (0:00:01.380) 0:00:01.395 ******
===============================================================================
run show version on remote devices -------------------------------------- 1.38s
berndonline@lab:~/cisco-lab-vagrant$
After the VMs are successfully booted you can connect again with vagrant ssh:
berndonline@lab:~/cisco-lab-vagrant$ vagrant ssh rtr-1 ************************************************************************** * IOSv is strictly limited to use for evaluation, demonstration and IOS * * education. IOSv is provided as-is and is not supported by Cisco's * * Technical Advisory Center. Any use or disclosure, in whole or in part, * * of the IOSv Software or Documentation to any third party for any * * purposes is expressly prohibited except as otherwise authorized by * * Cisco in writing. * ************************************************************************** router#show version Cisco IOS Software, IOSv Software (VIOS-ADVENTERPRISEK9-M), Version 15.6(2)T, RELEASE SOFTWARE (fc2) Technical Support: http://www.cisco.com/techsupport Copyright (c) 1986-2016 by Cisco Systems, Inc. Compiled Tue 22-Mar-16 16:19 by prod_rel_team ROM: Bootstrap program is IOSv router uptime is 1 minute System returned to ROM by reload System image file is "flash0:/vios-adventerprisek9-m" Last reload reason: Unknown reason .... berndonline@lab:~/cisco-lab-vagrant$ vagrant destroy ==> rtr-2: Removing domain... ==> rtr-1: Removing domain... berndonline@lab:~/cisco-lab-vagrant$
Basically thats it, your on-demand IOSv and IOS XE lab using Vagrant, ready for some automation and continuous integration testing.
The example Vagrantfiles you can find in my Github repository:
https://github.com/berndonline/cisco-lab-vagrant/blob/master/Vagrantfile-IOSXE
https://github.com/berndonline/cisco-lab-vagrant/blob/master/Vagrantfile-IOSv