I haven’t written much since the summer 2021 and I thought I start the New Year with a little update regarding OpenShift/OKD 4.9 Single Node cluster (SNO) installation. The single node type is not new because I have been using these All-in-One or Single Node clusters since OpenShift 3.x and it worked great until OpenShift 4.7. When RedHat released OpenShift 4.8 the single node installation stopped working because of issue with the control-plane because it expected three nodes for high availability and this installation method was possible till then but not officially supported by RedHat.
When the OpenShift 4.9 release was announced the single node installation method called SNO became a supported way for deploying OpenShift Edge clusters on bare-metal or virtual machine using the RedHat Cloud Assisted Installer.
This opened the possibility again to install OpenShift/OKD 4.9 as a single node (SNO) on any cloud provider like AWS, GCP or Azure through the openshift-install command line utility or through OpenShift Hive / Advanced Cluster Management operator.
The install-config.yaml for a single node cluster is pretty much the same like for a normal cluster only that you change the worker node replicas to zero and control-plane (master) nodes to one. Make sure your instance size has minimum 8x vCPUs and 32 GB of memory.
---
apiVersion: v1
baseDomain: k8s.domain.com
compute:
- name: worker
platform:
aws:
rootVolume:
iops: 100
size: 22
type: gp2
type: m5.2xlarge
replicas: 0
controlPlane:
name: master
platform:
aws:
rootVolume:
iops: 100
size: 22
type: gp2
type: m5.2xlarge
replicas: 1
metadata:
creationTimestamp: null
name: okd-eu-west-1
networking:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
machineCIDR: 10.0.0.0/16
networkType: OpenShiftSDN
serviceNetwork:
- 172.30.0.0/16
platform:
aws:
region: eu-west-1
pullSecret: ""
sshKey: ""
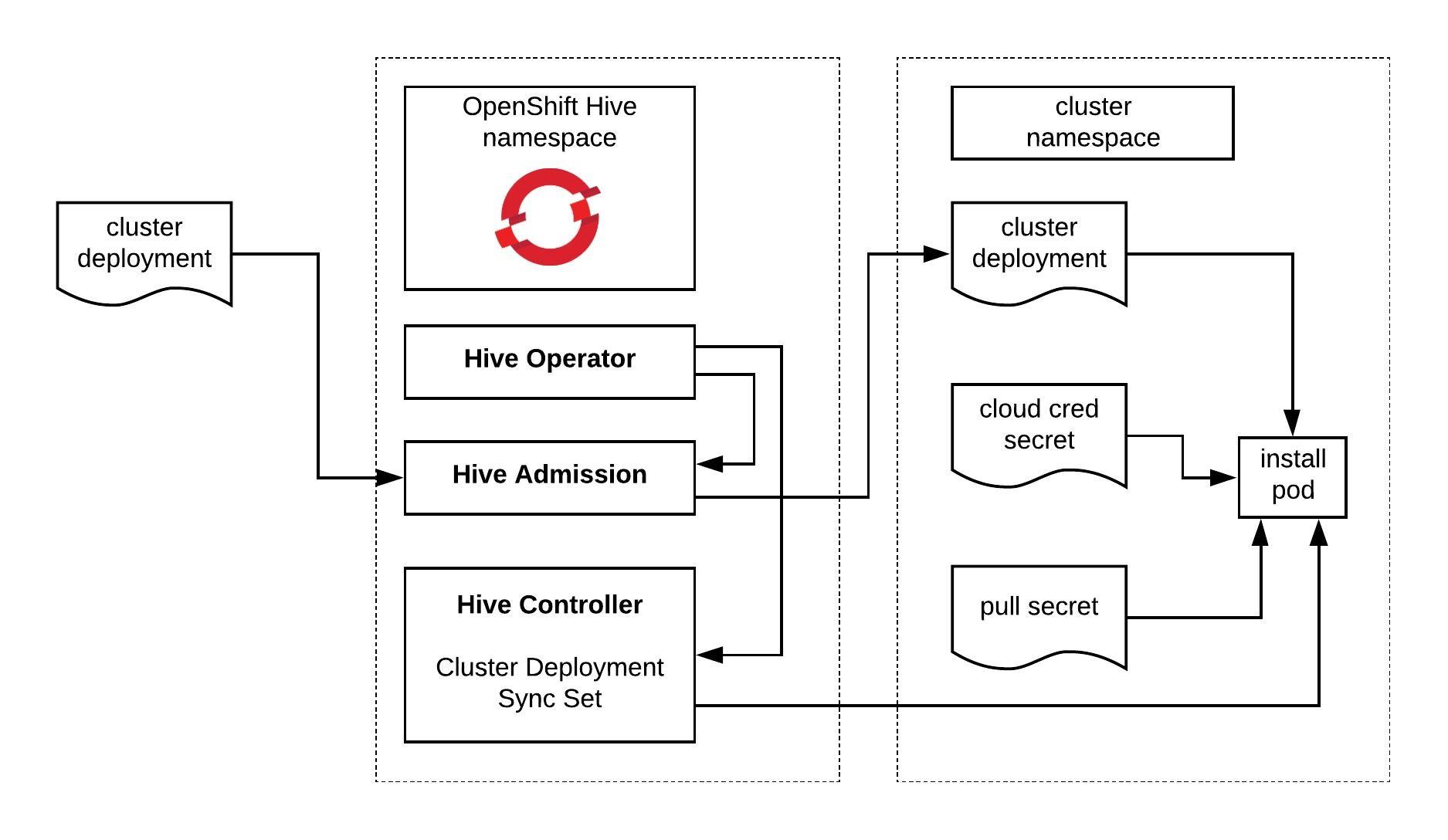
I am using OpenShift Hive for installing the OKD 4.9 single node cluster which requires Kubernetes to run the Hive operator.
Create a install-config secret:
$ kubectl create secret generic install-config -n okd --from-file=install-config.yaml=./okd-sno-install-config.yaml
In the ClusterDeployment you specify AWS credentials, reference the install-config and the release image for OKD 4.9. Here you can find the latest OKD release image tags: https://quay.io/repository/openshift/okd
---
apiVersion: hive.openshift.io/v1
kind: ClusterDeployment
metadata:
creationTimestamp: null
name: okd-eu-west-1
namespace: okd
spec:
baseDomain: k8s.domain.com
clusterName: okd-eu-west-1
controlPlaneConfig:
servingCertificates: {}
installed: false
platform:
aws:
credentialsSecretRef:
name: aws-creds
region: eu-west-1
provisioning:
releaseImage: quay.io/openshift/okd:4.9.0-0.okd-2022-01-14-230113
installConfigSecretRef:
name: install-config
pullSecretRef:
name: pull-secret
Apply the cluster deployment and wait for Hive to install the OpenShift/OKD cluster.
$ kubectl apply -f ./okd-clusterdeployment.yaml
The provision pod will output the messages from the openshift-install binary and the cluster will be finish the installation in around 35mins.
$ kubectl logs okd-eu-west-1-0-8vhnf-provision-qrjrg -c hive -f time="2022-01-15T15:51:32Z" level=debug msg="Couldn't find install logs provider environment variable. Skipping." time="2022-01-15T15:51:32Z" level=debug msg="checking for SSH private key" installID=m2zcxsds time="2022-01-15T15:51:32Z" level=info msg="unable to initialize host ssh key" error="cannot configure SSH agent as SSH_PRIV_KEY_PATH is unset or empty" installID=m2zcxsds time="2022-01-15T15:51:32Z" level=info msg="waiting for files to be available: [/output/openshift-install /output/oc]" installID=m2zcxsds time="2022-01-15T15:51:32Z" level=info msg="found file" installID=m2zcxsds path=/output/openshift-install time="2022-01-15T15:51:32Z" level=info msg="found file" installID=m2zcxsds path=/output/oc time="2022-01-15T15:51:32Z" level=info msg="all files found, ready to proceed" installID=m2zcxsds time="2022-01-15T15:51:35Z" level=info msg="copied /output/openshift-install to /home/hive/openshift-install" installID=m2zcxsds time="2022-01-15T15:51:36Z" level=info msg="copied /output/oc to /home/hive/oc" installID=m2zcxsds time="2022-01-15T15:51:36Z" level=info msg="copying install-config.yaml" installID=m2zcxsds time="2022-01-15T15:51:36Z" level=info msg="copied /installconfig/install-config.yaml to /output/install-config.yaml" installID=m2zcxsds time="2022-01-15T15:51:36Z" level=info msg="waiting for files to be available: [/output/.openshift_install.log]" installID=m2zcxsds time="2022-01-15T15:51:36Z" level=info msg="cleaning up from past install attempts" installID=m2zcxsds time="2022-01-15T15:51:36Z" level=warning msg="skipping cleanup as no infra ID set" installID=m2zcxsds time="2022-01-15T15:51:36Z" level=debug msg="object does not exist" installID=m2zcxsds object=okd/okd-eu-west-1-0-8vhnf-admin-kubeconfig time="2022-01-15T15:51:36Z" level=debug msg="object does not exist" installID=m2zcxsds object=okd/okd-eu-west-1-0-8vhnf-admin-password time="2022-01-15T15:51:36Z" level=info msg="generating assets" installID=m2zcxsds time="2022-01-15T15:51:36Z" level=info msg="running openshift-install create manifests" installID=m2zcxsds time="2022-01-15T15:51:36Z" level=info msg="running openshift-install binary" args="[create manifests]" installID=m2zcxsds time="2022-01-15T15:51:37Z" level=info msg="found file" installID=m2zcxsds path=/output/.openshift_install.log time="2022-01-15T15:51:37Z" level=info msg="all files found, ready to proceed" installID=m2zcxsds time="2022-01-15T15:51:36Z" level=debug msg="OpenShift Installer unreleased-master-5011-geb132dae953888e736c382f1176c799c0e1aa49e-dirty" time="2022-01-15T15:51:36Z" level=debug msg="Built from commit eb132dae953888e736c382f1176c799c0e1aa49e" time="2022-01-15T15:51:36Z" level=debug msg="Fetching Master Machines..." time="2022-01-15T15:51:36Z" level=debug msg="Loading Master Machines..." time="2022-01-15T15:51:36Z" level=debug msg=" Loading Cluster ID..." time="2022-01-15T15:51:36Z" level=debug msg=" Loading Install Config..." time="2022-01-15T15:51:36Z" level=debug msg=" Loading SSH Key..." time="2022-01-15T15:51:36Z" level=debug msg=" Loading Base Domain..." .... time="2022-01-15T16:14:17Z" level=debug msg="Still waiting for the cluster to initialize: Working towards 4.9.0-0.okd-2022-01-14-230113" time="2022-01-15T16:14:31Z" level=debug msg="Still waiting for the cluster to initialize: Working towards 4.9.0-0.okd-2022-01-14-230113: 529 of 744 done (71% complete)" time="2022-01-15T16:14:32Z" level=debug msg="Still waiting for the cluster to initialize: Working towards 4.9.0-0.okd-2022-01-14-230113: 585 of 744 done (78% complete)" time="2022-01-15T16:14:47Z" level=debug msg="Still waiting for the cluster to initialize: Working towards 4.9.0-0.okd-2022-01-14-230113: 702 of 744 done (94% complete)" time="2022-01-15T16:15:02Z" level=debug msg="Still waiting for the cluster to initialize: Working towards 4.9.0-0.okd-2022-01-14-230113: 703 of 744 done (94% complete)" time="2022-01-15T16:15:32Z" level=debug msg="Still waiting for the cluster to initialize: Working towards 4.9.0-0.okd-2022-01-14-230113: 708 of 744 done (95% complete)" time="2022-01-15T16:15:47Z" level=debug msg="Still waiting for the cluster to initialize: Working towards 4.9.0-0.okd-2022-01-14-230113: 720 of 744 done (96% complete)" time="2022-01-15T16:16:02Z" level=debug msg="Still waiting for the cluster to initialize: Working towards 4.9.0-0.okd-2022-01-14-230113: 722 of 744 done (97% complete)" time="2022-01-15T16:17:17Z" level=debug msg="Still waiting for the cluster to initialize: Some cluster operators are still updating: authentication, console, monitoring" time="2022-01-15T16:18:02Z" level=debug msg="Cluster is initialized" time="2022-01-15T16:18:02Z" level=info msg="Waiting up to 10m0s for the openshift-console route to be created..." time="2022-01-15T16:18:02Z" level=debug msg="Route found in openshift-console namespace: console" time="2022-01-15T16:18:02Z" level=debug msg="OpenShift console route is admitted" time="2022-01-15T16:18:02Z" level=info msg="Install complete!" time="2022-01-15T16:18:02Z" level=info msg="To access the cluster as the system:admin user when using 'oc', run 'export KUBECONFIG=/output/auth/kubeconfig'" time="2022-01-15T16:18:02Z" level=info msg="Access the OpenShift web-console here: https://console-openshift-console.apps.okd-eu-west-1.k8s.domain.com" time="2022-01-15T16:18:02Z" level=debug msg="Time elapsed per stage:" time="2022-01-15T16:18:02Z" level=debug msg=" cluster: 6m35s" time="2022-01-15T16:18:02Z" level=debug msg=" bootstrap: 34s" time="2022-01-15T16:18:02Z" level=debug msg="Bootstrap Complete: 12m46s" time="2022-01-15T16:18:02Z" level=debug msg=" API: 4m2s" time="2022-01-15T16:18:02Z" level=debug msg=" Bootstrap Destroy: 1m15s" time="2022-01-15T16:18:02Z" level=debug msg=" Cluster Operators: 4m59s" time="2022-01-15T16:18:02Z" level=info msg="Time elapsed: 26m13s" time="2022-01-15T16:18:03Z" level=info msg="command completed successfully" installID=m2zcxsds time="2022-01-15T16:18:03Z" level=info msg="saving installer output" installID=m2zcxsds time="2022-01-15T16:18:03Z" level=info msg="install completed successfully" installID=m2zcxsds
Check the cluster deployment and get the kubeadmin password from the secret the Hive operator created during the installation and login to the web console:
$ kubectl get clusterdeployments
NAME PLATFORM REGION CLUSTERTYPE INSTALLED INFRAID VERSION POWERSTATE AGE
okd-eu-west-1 aws eu-west-1 true okd-eu-west-1-l4g4n 4.9.0 Running 39m
$ kubectl get secrets okd-eu-west-1-0-8vhnf-admin-password -o jsonpath={.data.password} | base64 -d
EP5Fs-TZrKj-Vtst6-5GWZ9
The cluster details show that the control plane runs as single master node:
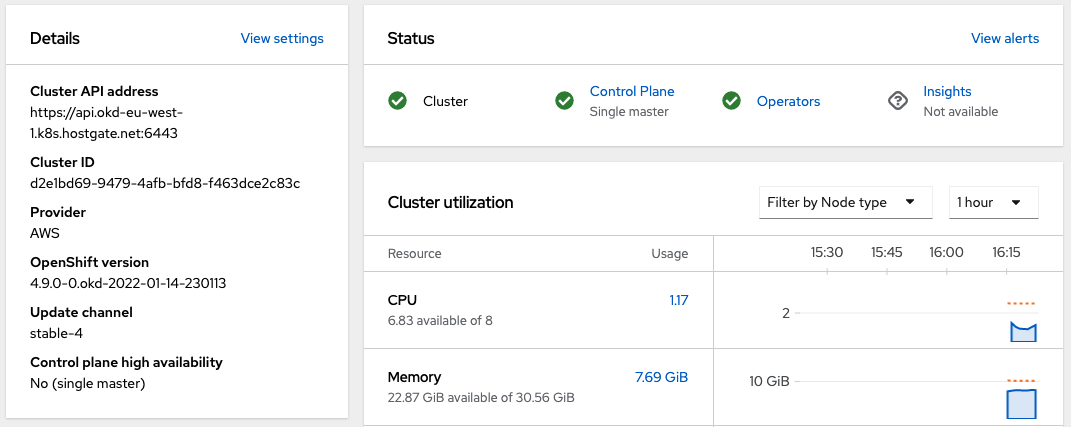
Your cluster has a single combined master/worker node:
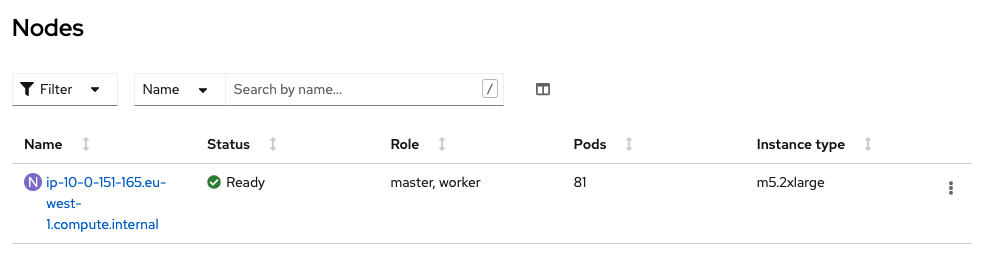
These single node type clusters can be used in combination with OpenShift Hive ClusterPools to have an amount of pre-installed OpenShift/OKD clusters available for automated tests or as temporary development environment.
apiVersion: hive.openshift.io/v1
kind: ClusterPool
metadata:
name: okd-eu-west-1-pool
namespace: okd
spec:
baseDomain: k8s.domain.com
imageSetRef:
name: 4.9.0-0.okd-2022-01-14
installConfigSecretTemplateRef:
name: install-config
platform:
aws:
credentialsSecretRef:
name: aws-creds
region: eu-west-1
pullSecretRef:
name: pull-secret
size: 3
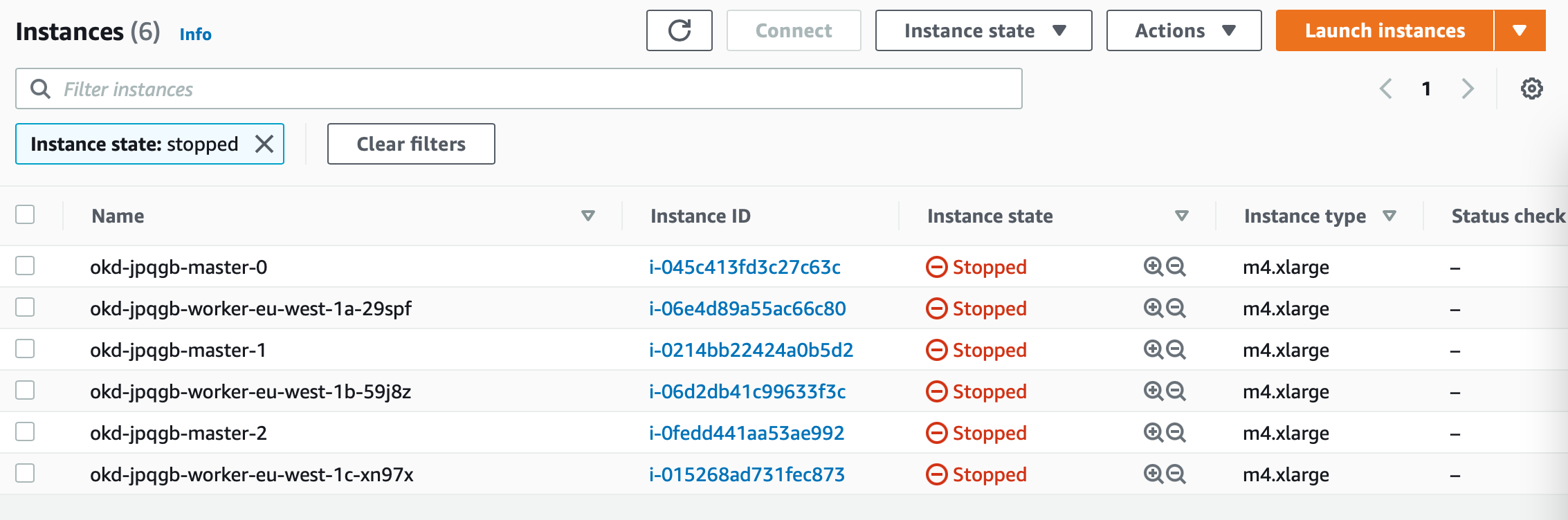
The clusters are hibernating (shutdown) in the pool and will be powered on when you apply the ClusterClaim to allocate a cluster with a lifetime set to 8 hours. After 8 hours the cluster gets automatically deleted by the Hive operator.
apiVersion: hive.openshift.io/v1 kind: ClusterClaim metadata: name: test-1 namespace: okd spec: clusterPoolName: okd-eu-west-1-pool lifetime: 8h
This sums up how to deploy a OpenShift/OKD 4.9 as single node cluster. I hope this article is helpful and leave a comment if you have questions.