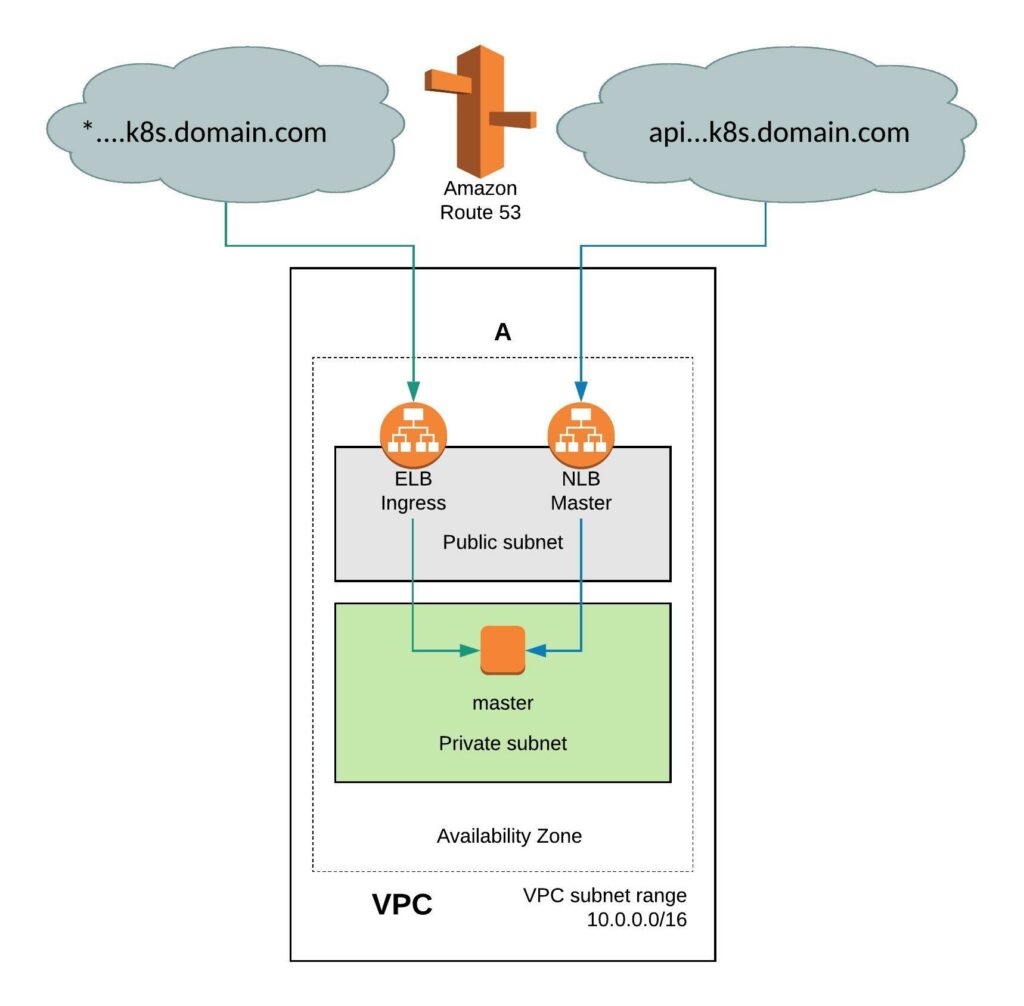
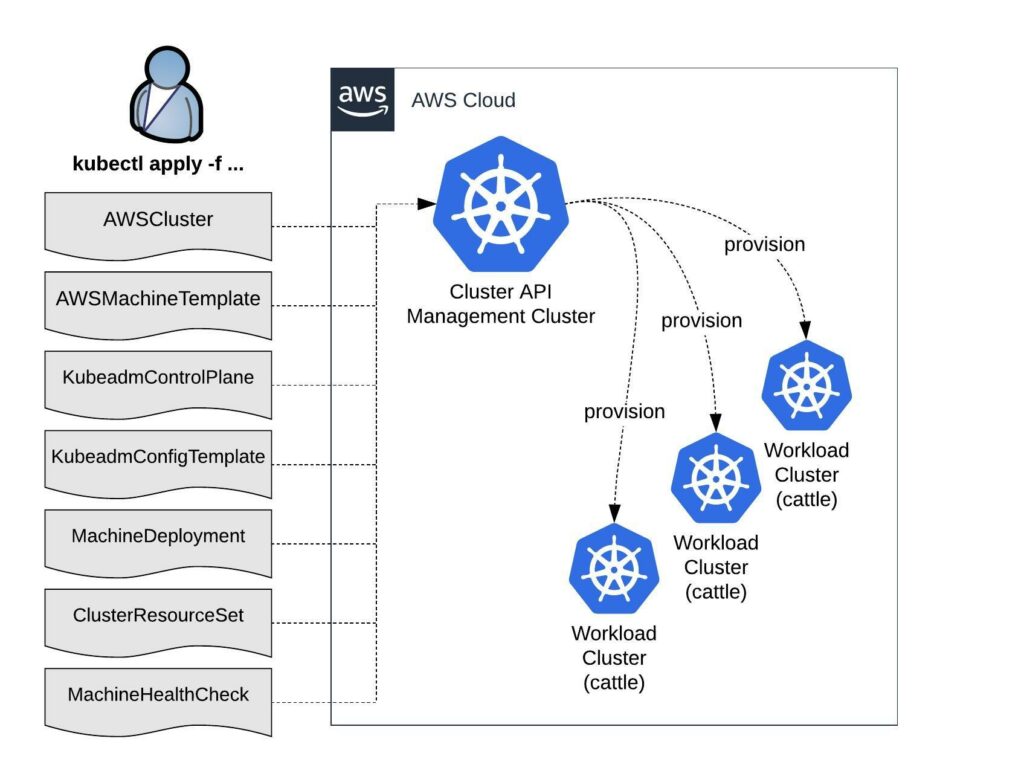
What does GitOps mean and how you run this at scale with Kubernetes? GitOps is basically a framework that takes traditional DevOps practices which where used for application development and apply them to platform automation.
This is nothing new and some maybe have done similar type of automation in the past but this wasn’t called GitOps back then. Kubernetes is great because of it’s declarative configuration management which makes it very easy to configure. This can become a challenge when you suddenly have to run 5, 10, 20 or 40 of these clusters across various cloud providers and multiple environments. We need a cluster management system feeding configuration from a code repository to run all our Kubernetes “cattle” workload clusters.
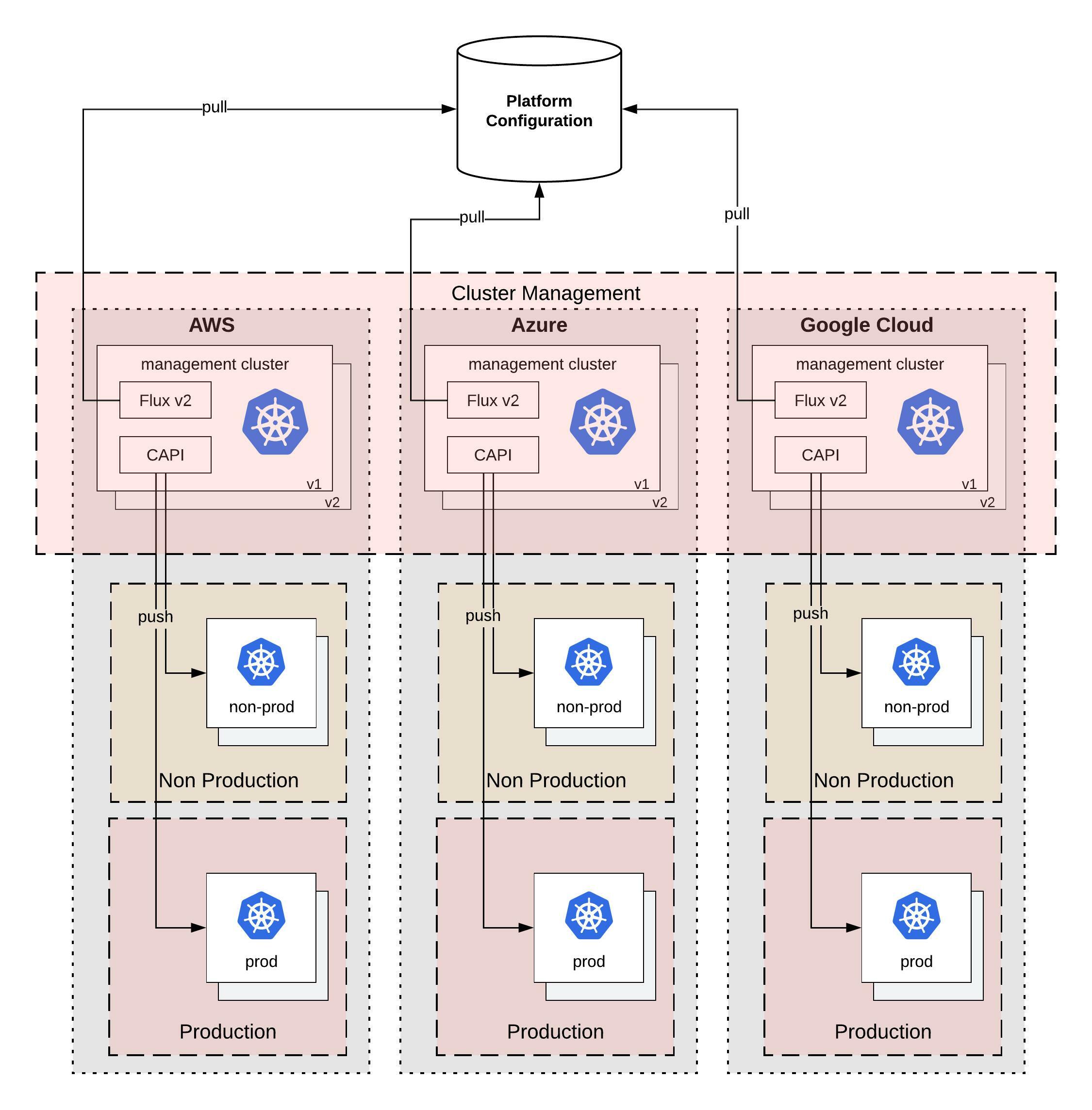
What I am trying to achieve with this design; that you can easily horizontally scale not only your workload clusters but also your cluster management system which is versioned across multiple cloud providers like you see in the diagram above.
There is of course a technical problem to all of this, finding the right tools to solve the problem and which work well together. In my example I will use the Cluster API for provisioning and managing the lifecycle of these Kubernetes workload clusters. Then we need Flux CD for the configuration management both the cluster management which runs the Cluster API components but also the configuration for the workload clusters. The Cluster API you can also replace with OpenShift Hive to run instead OKD or RedHat OpenShift clusters.
Another problem we need to think about is version control and the branching model for the platform configuration. The structure of the configuration is important but also how you implement changes or the versioning of your configuration through releases. I highly recommend reading about Trunk Based Development which is a modern branching model and specifically solves the versioning problem for us.
Git repository and folder structure
We need a git repository for storing the platform configuration both for the management- and workload-clusters, and the tenant namespace configuration (this also can be stored in a separate repositories). Let’s go through the folder structure of the repository and I will explain this in more detail. Checkout my example repository for more detail: github.com/berndonline/k8s-gitops-at-scale.
- The features folder on the top-level will store configuration for specific features we want to enable and apply to our clusters (both management and worker). Under each <feature name> you find two subfolders for namespace(d)- and cluster-wide (non-namespaced) configuration. Features are part of platform configuration which will be promoted between environments. You will see namespaced and non-namespaced subfolders throughout the folder structure which is basically to group your configuration files.
├── features │ ├── access-control │ │ └── non-namespaced │ ├── helloworld-operator │ │ ├── namespaced │ │ └── non-namespaced │ └── ingress-nginx │ ├── namespaced │ └── non-namespaced
- The providers folder will store the configuration based on cloud provider <name> and the <version> of your cluster management. The version below the cloud provider folder is needed to be able to spin up new management clusters in the future. You can be creative with the folder structure and have management cluster per environment and/or instead of the version if required. The mgmt folder will store the configuration for the management cluster which includes manifests for Flux CD controllers, the Cluster API to spin-up workload clusters which are separated by cluster name and anything else you want to configure on your management cluster. The clusters folder will store configuration for all workload clusters separated based on <environment> and common (applies across multiple clusters in the same environment) and by <cluster name> (applies to a dedicated cluster).
├── providers │ └── aws │ └── v1 │ ├── clusters │ │ ├── non-prod │ │ │ ├── common │ │ │ │ ├── namespaced │ │ │ │ │ └── non-prod-common │ │ │ │ └── non-namespaced │ │ │ │ └── non-prod-common │ │ │ └── non-prod-eu-west-1 │ │ │ ├── namespaced │ │ │ │ └── non-prod-eu-west-1 │ │ │ └── non-namespaced │ │ │ └── non-prod-eu-west-1 │ │ └── prod │ │ ├── common │ │ │ ├── namespaced │ │ │ │ └── prod-common │ │ │ └── non-namespaced │ │ │ └── prod-common │ │ └── prod-eu-west-1 │ │ ├── namespaced │ │ │ └── prod-eu-west-1 │ │ └── non-namespaced │ │ └── prod-eu-west-1 │ └── mgmt │ ├── namespaced │ │ ├── flux-system │ │ ├── non-prod-eu-west-1 │ │ └── prod-eu-west-1 │ └── non-namespaced │ ├── non-prod-eu-west-1 │ └── prod-eu-west-1
- The tenants folder will store the namespace configuration of the onboarded teams and is applied to our workload clusters. Similar to the providers folder tenants has subfolders based on the cloud provider <name> and below subfolders for common (applies across environments) and <environments> (applied to a dedicated environment) configuration. There you find the tenant namespace <name> and all the needed manifests to create and configure the namespace/s.
└── tenants └── aws ├── common │ └── dummy ├── non-prod │ └── dummy └── prod └── dummy
Why do we need a common folder for tenants? The common folder will contain namespace configuration which will be promoted between the environments from non-prod to prod using a release but more about release and promotion you find more down below.
Configuration changes
Applying changes to your platform configuration has to follow the Trunk Based Development model of doing small incremental changes through feature branches.
Let’s look into an example change the our dummy tenant onboarding pull-request. You see that I checked-out a branch called “tenant-dummy” to apply my changes, then push and publish the branch in the repository to raised the pull-request.
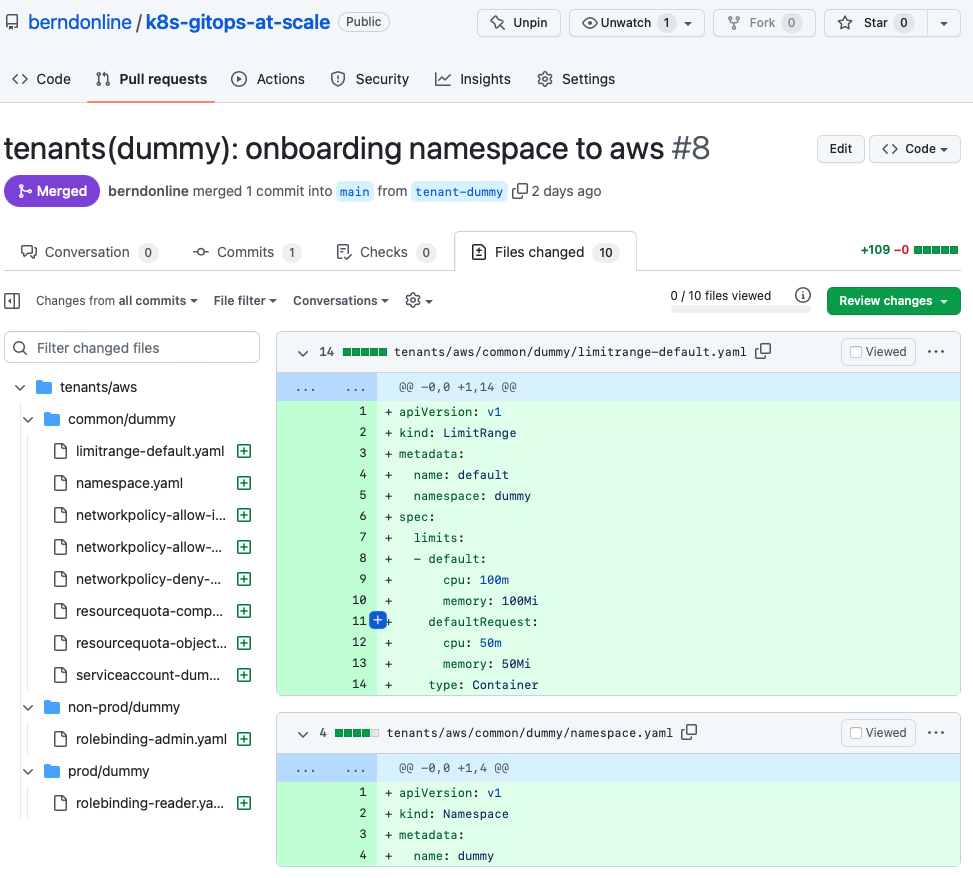
Important is that your commit messages and pull-request name are following a strict naming convention.
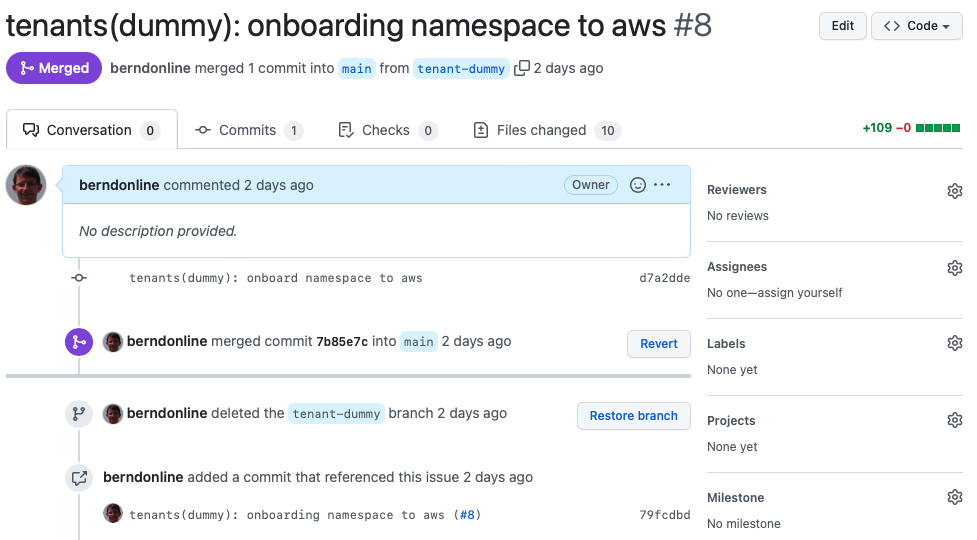
I would also strongly recommend to squash your commit messages into the name of your pull-request. This will keep your git history clean.
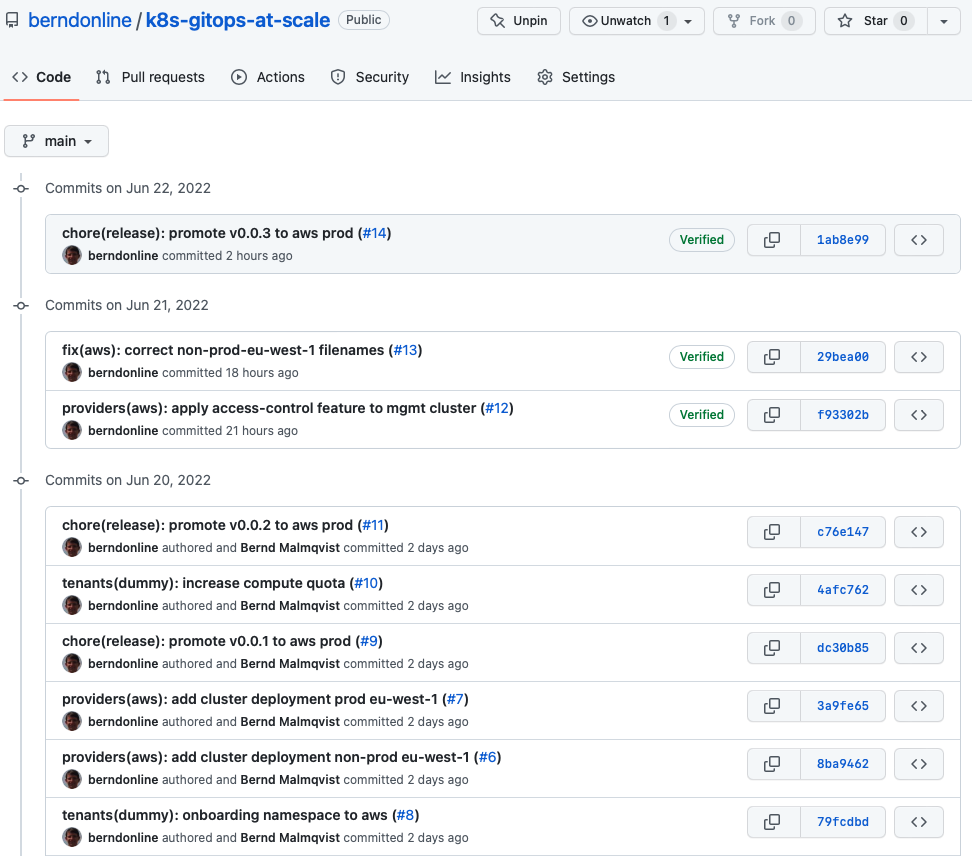
This naming convention makes it easier later for auto-generating your release notes when you publish your release. Having the clean well formatted git history combined with your release notes nicely cross references your changes for to a particular release tag.
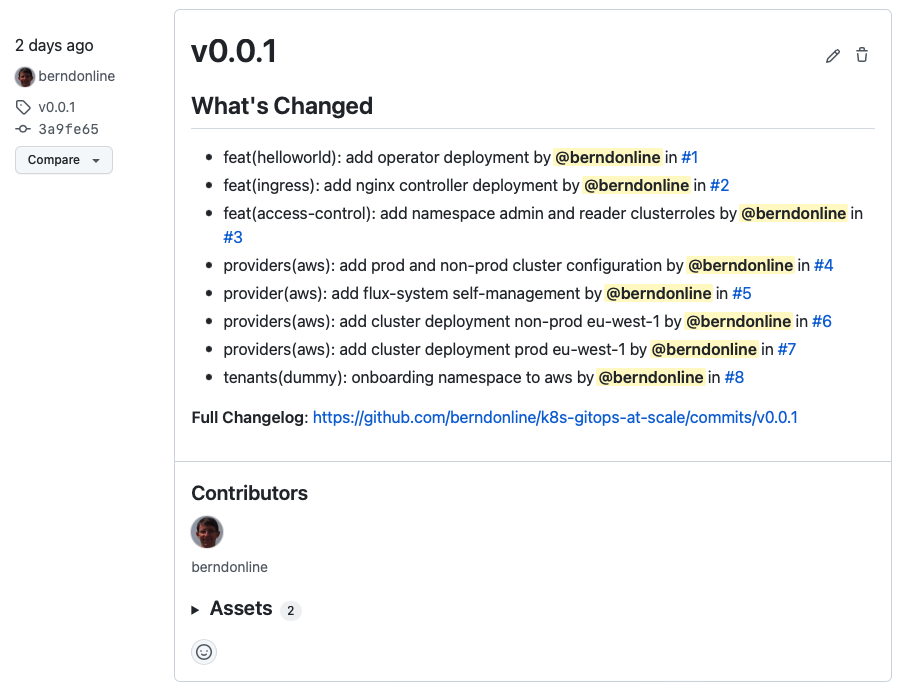
More about creating a release a bit later in this article.
GitOps configuration
The configuration from the platform repository gets pulled on the management cluster using different gitrepository resources following the main branch or a version tag.
$ kubectl get gitrepositories.source.toolkit.fluxcd.io -A NAMESPACE NAME URL AGE READY STATUS flux-system main ssh://[email protected]/berndonline/k8s-gitops-at-scale 2d True stored artifact for revision 'main/ee3e71efb06628775fa19e9664b9194848c6450e' flux-system release ssh://[email protected]/berndonline/k8s-gitops-at-scale 2d True stored artifact for revision 'v0.0.2/a5a5edd1194b629f6b41977483dca49aaad957ff'
The kustomization resources will then render and apply the configuration locally to the management cluster (diagram left-side) or remote clusters to our non-prod and prod workload clusters (diagram right-side) using the kubeconfig of the cluster created by the Cluster API stored during the bootstrap.
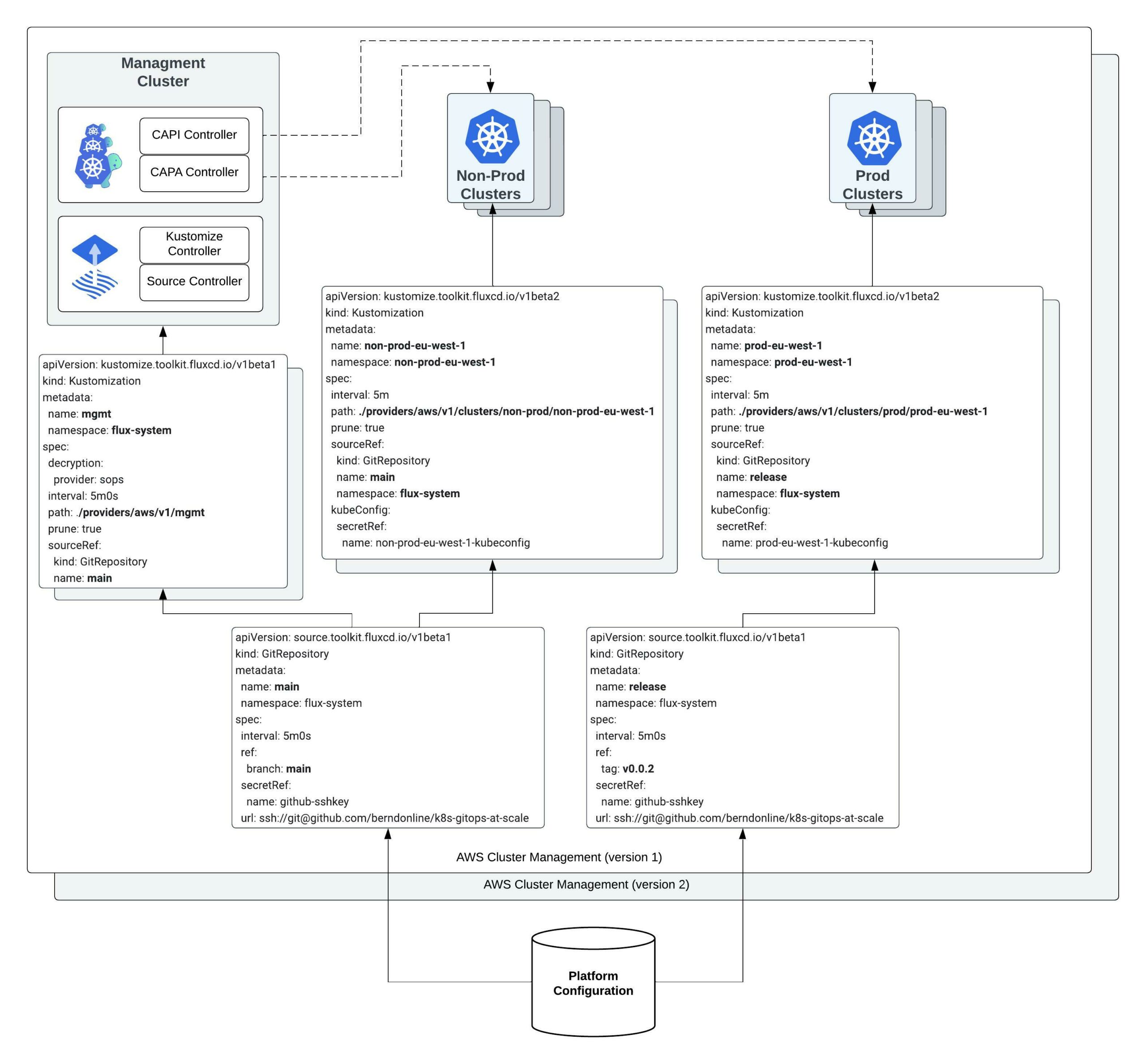
There are multiple kustomization resources to apply configuration based off the folder structure which I explained above. See the output below and checkout the repository for more details.
$ kubectl get kustomizations.kustomize.toolkit.fluxcd.io -A NAMESPACE NAME AGE READY STATUS flux-system feature-access-control 13h True Applied revision: v0.0.2/a5a5edd1194b629f6b41977483dca49aaad957ff flux-system mgmt 2d True Applied revision: main/ee3e71efb06628775fa19e9664b9194848c6450e non-prod-eu-west-1 common 21m True Applied revision: main/ee3e71efb06628775fa19e9664b9194848c6450e non-prod-eu-west-1 feature-access-control 21m True Applied revision: main/ee3e71efb06628775fa19e9664b9194848c6450e non-prod-eu-west-1 feature-helloworld-operator 21m True Applied revision: main/ee3e71efb06628775fa19e9664b9194848c6450e non-prod-eu-west-1 feature-ingress-nginx 21m True Applied revision: main/ee3e71efb06628775fa19e9664b9194848c6450e non-prod-eu-west-1 non-prod-eu-west-1 21m True Applied revision: main/ee3e71efb06628775fa19e9664b9194848c6450e non-prod-eu-west-1 tenants-common 21m True Applied revision: main/ee3e71efb06628775fa19e9664b9194848c6450e non-prod-eu-west-1 tenants-non-prod 21m True Applied revision: main/ee3e71efb06628775fa19e9664b9194848c6450e prod-eu-west-1 common 15m True Applied revision: v0.0.2/a5a5edd1194b629f6b41977483dca49aaad957ff prod-eu-west-1 feature-access-control 15m True Applied revision: v0.0.2/a5a5edd1194b629f6b41977483dca49aaad957ff prod-eu-west-1 feature-helloworld-operator 15m True Applied revision: v0.0.2/a5a5edd1194b629f6b41977483dca49aaad957ff prod-eu-west-1 feature-ingress-nginx 15m True Applied revision: v0.0.2/a5a5edd1194b629f6b41977483dca49aaad957ff prod-eu-west-1 prod-eu-west-1 15m True Applied revision: v0.0.2/a5a5edd1194b629f6b41977483dca49aaad957ff prod-eu-west-1 tenants-common 15m True Applied revision: v0.0.2/a5a5edd1194b629f6b41977483dca49aaad957ff prod-eu-west-1 tenants-prod 15m True Applied revision: v0.0.2/a5a5edd1194b629f6b41977483dca49aaad957ff
Release and promotion
The GitOps framework doesn’t explain about how to do promotion to higher environments and this is where the Trunk Based Development model comes in helpful together with the gitrepository resource to be able to pull a tagged version instead of a branch.
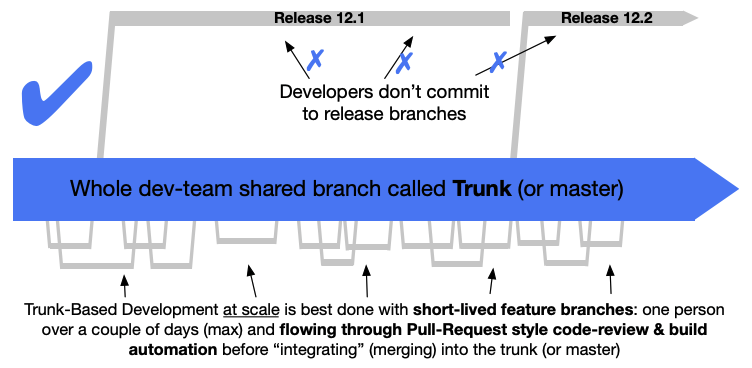
This allows us applying configuration first to lower environments to non-prod following the main branch, means pull-requests which are merged will be applied instantly. Configuration for higher environments to production requires to create a version tag and publish a release in the repository.
Why using a tag and not a release branch? A tag in your repository is a point in time snapshot of your configuration and can’t be easily modified which is required for creating the release. A branch on the other hand can be modified using pull-requests and you end up with lots of release branches which is less ideal.
To create a new version tag in the git repository I use the following commands:
$ git tag v0.0.3 $ git push origin --tags Total 0 (delta 0), reused 0 (delta 0) To github.com:berndonline/k8s-gitops-at-scale.git * [new tag] v0.0.3 -> v0.0.3
This doesn’t do much after we pushed the new tag because the gitrepository release is set to v0.0.2 but I can see the new tag is available in the repository.
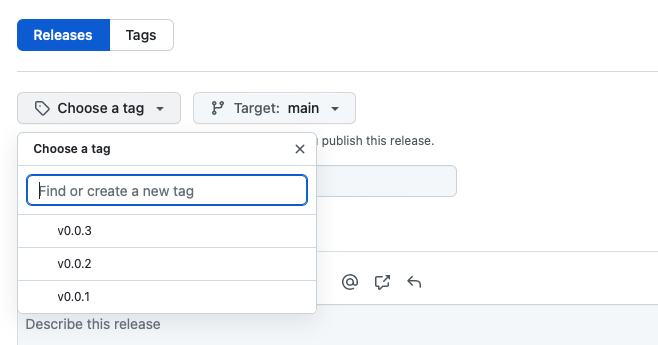
In the repository I can go to releases and click on “Draft a new release” and choose the new tag v0.0.3 I pushed previously.
The release notes you see below can be auto-generate from the pull-requests you merged between v0.0.2 and v0.0.3 by clicking “Generate release notes”. To finish this off save and publish the release.
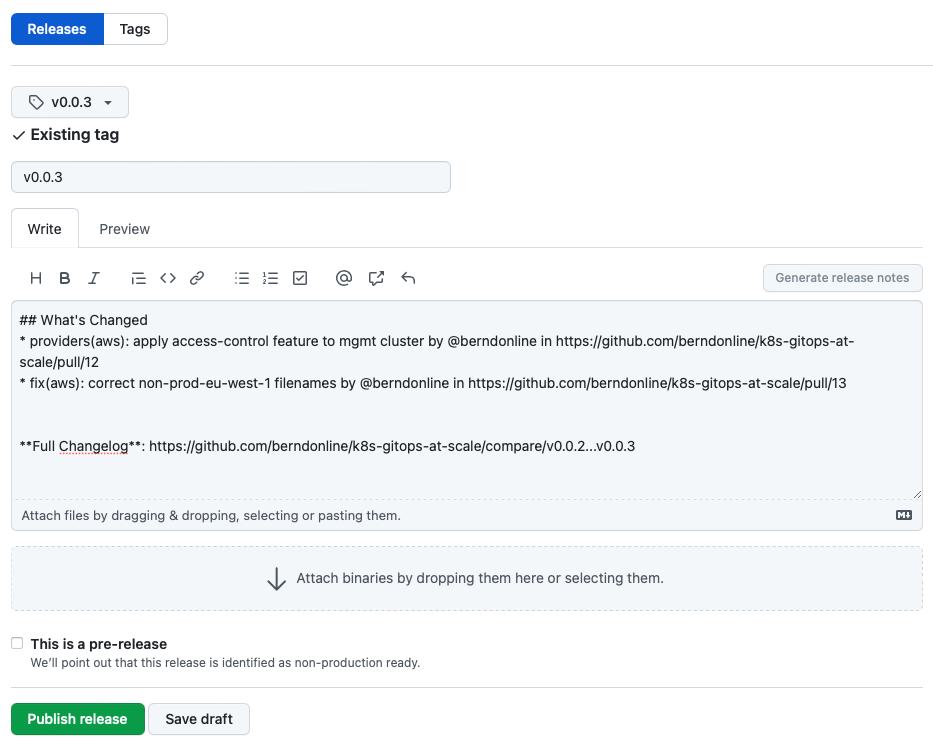
The release is publish and release notes are visible to everyone which is great for product teams on your platform because they will get visibility about upcoming changes including their own modifications to namespace configuration.
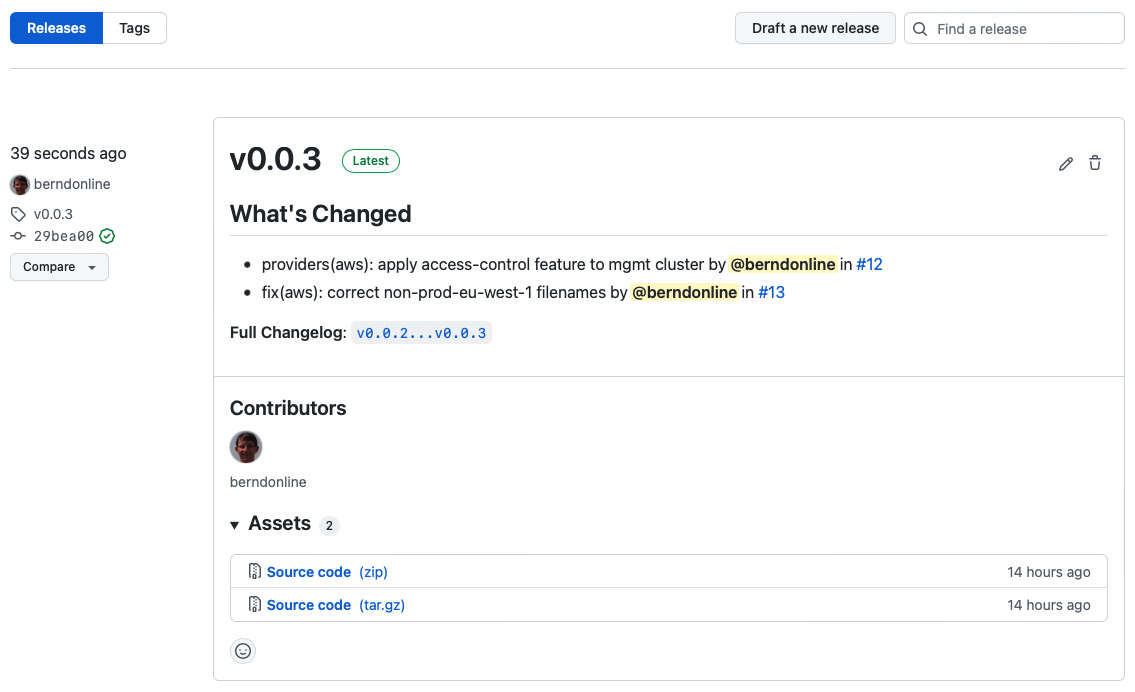
Until now all the changes are applied to our lower non-prod environment following the main branch and for doing the promotion we need to raise a pull-request and update the gitrepository release the new version v0.0.3.
If you follow ITIL change procedures then this is the point where you would normally raise a change for merging your pull-request because this triggers the rollout of your configuration to production.
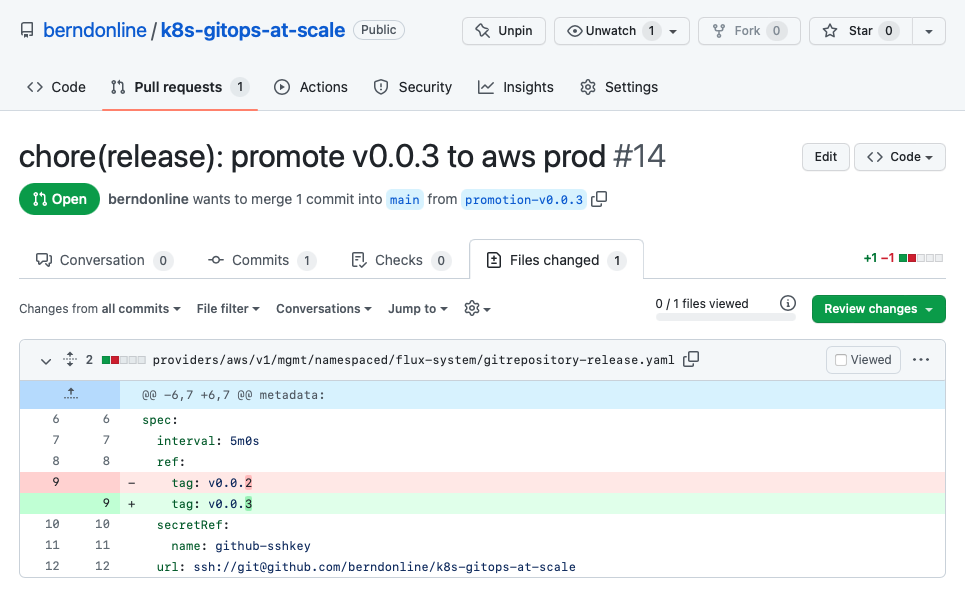
When the pull-request is merged the release gitrepository is updated by the kustomization resources through the main branch.
$ kubectl get gitrepositories.source.toolkit.fluxcd.io -A NAMESPACE NAME URL AGE READY STATUS flux-system main ssh://[email protected]/berndonline/k8s-gitops 2d True stored artifact for revision 'main/83133756708d2526cca565880d069445f9619b70' flux-system release ssh://[email protected]/berndonline/k8s-gitops 2d True stored artifact for revision 'v0.0.3/ee3e71efb06628885fa19e9664b9198a8c6450e8'
Shortly after the kustomization resources referencing the release will reconcile and automatically push down the new rendered configuration to the production clusters.
$ kubectl get kustomizations.kustomize.toolkit.fluxcd.io -A NAMESPACE NAME AGE READY STATUS flux-system feature-access-control 13h True Applied revision: v0.0.3/ee3e71efb06628885fa19e9664b9198a8c6450e8 flux-system mgmt 2d True Applied revision: main/83133756708d2526cca565880d069445f9619b70 non-prod-eu-west-1 common 31m True Applied revision: main/83133756708d2526cca565880d069445f9619b70 non-prod-eu-west-1 feature-access-control 31m True Applied revision: main/83133756708d2526cca565880d069445f9619b70 non-prod-eu-west-1 feature-helloworld-operator 31m True Applied revision: main/83133756708d2526cca565880d069445f9619b70 non-prod-eu-west-1 feature-ingress-nginx 31m True Applied revision: main/83133756708d2526cca565880d069445f9619b70 non-prod-eu-west-1 non-prod-eu-west-1 31m True Applied revision: main/83133756708d2526cca565880d069445f9619b70 non-prod-eu-west-1 tenants-common 31m True Applied revision: main/83133756708d2526cca565880d069445f9619b70 non-prod-eu-west-1 tenants-non-prod 31m True Applied revision: main/83133756708d2526cca565880d069445f9619b70 prod-eu-west-1 common 26m True Applied revision: v0.0.3/ee3e71efb06628885fa19e9664b9198a8c6450e8 prod-eu-west-1 feature-access-control 26m True Applied revision: v0.0.3/ee3e71efb06628885fa19e9664b9198a8c6450e8 prod-eu-west-1 feature-helloworld-operator 26m True Applied revision: v0.0.3/ee3e71efb06628885fa19e9664b9198a8c6450e8 prod-eu-west-1 feature-ingress-nginx 26m True Applied revision: v0.0.3/ee3e71efb06628885fa19e9664b9198a8c6450e8 prod-eu-west-1 prod-eu-west-1 26m True Applied revision: v0.0.3/ee3e71efb06628885fa19e9664b9198a8c6450e8 prod-eu-west-1 tenants-common 26m True Applied revision: v0.0.3/ee3e71efb06628885fa19e9664b9198a8c6450e8 prod-eu-west-1 tenants-prod 26m True Applied revision: v0.0.3/ee3e71efb06628885fa19e9664b9198a8c6450e8
Why using Kustomize for managing the configuration and not Helm? I know the difficulties of managing these raw YAML manifests. Kustomize gets you going quick where with Helm there is a higher initial effort writing your Charts. In my next article I will focus specifically on Helm.
I showed a very simplistic example having a single cloud provider (aws) and a single management cluster but as you have seen you can easily add Azure or Google cloud providers in your configuration and scale horizontally. I think this is what makes Kubernetes and controllers like Flux CD great together that you don’t need to have complex pipelines or workflows to rollout and promote your changes completely pipeline-less.