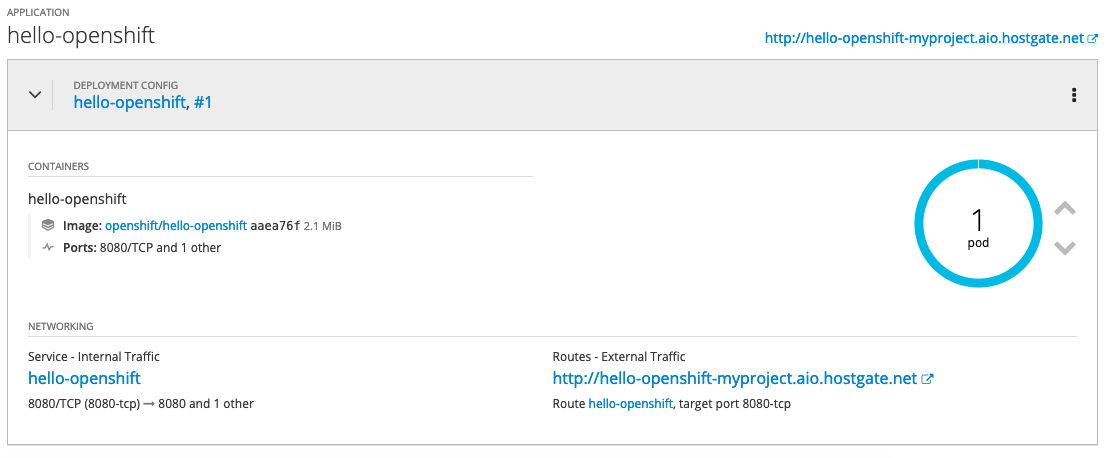
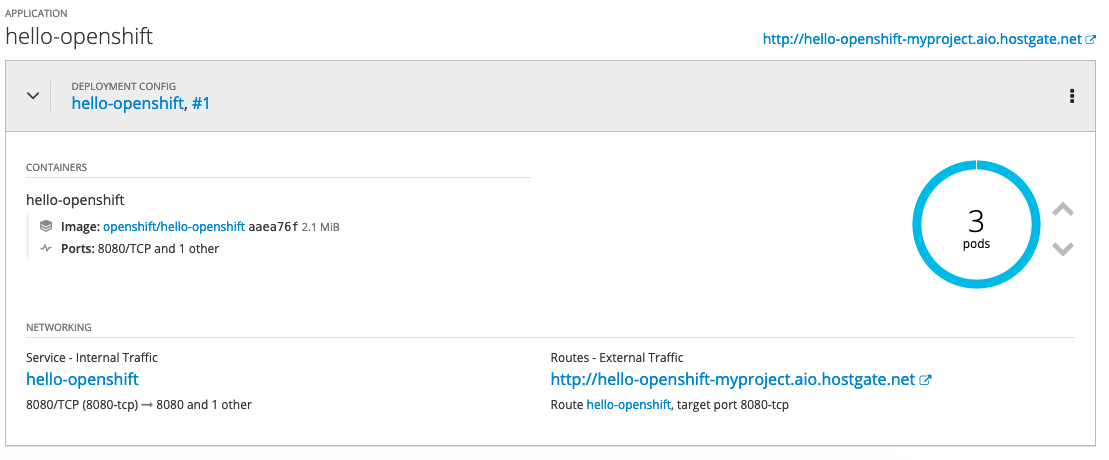
In the past few weeks I started to learn Go and beginners like me can make quick progress once you understand the structure and some basics about the programming language. I felt that from all the learning and reading I’ve done on Go and Kubernetes operators, I had enough knowledge to start writing my own Kubernetes operator in Go.

At the beginning of last year, RedHat released the operator-sdk which helps to create the scaffolding for writing your own operators in Ansible, Helm or natively in Go. There has been quite a few changes along the way around the operator-sdk and it is maturing a lot over the course of the past year.
The instructions on how to install Go can be found on the Go website and we need the latest version of the operator-sdk:
$ wget https://github.com/operator-framework/operator-sdk/releases/download/v1.2.0/operator-sdk-v1.2.0-x86_64-linux-gnu
$ mv operator-sdk-v1.2.0-x86_64-linux-gnu operator-sdk
$ sudo mv operator-sdk /usr/local/bin/
Create a new folder and start to initialise the project. You see that I have already set the option --domain so all API groups will be <-group->.helloworld.io. The --repo option allows me to create the project folder outside of my $GOPATH environment. Infos about the folder structure you can find in the Kubebuilder documentation:
$ mkdir k8s-helloworld-operator
$ cd k8s-helloworld-operator
$ operator-sdk init --domain=helloworld.io --repo=github.com/berndonline/k8s-helloworld-operator
The last thing we need before we start writing the operator is to create a new API and Controller and this will scaffold the operator API at api/v1alpha1/operator_types.go and the controller at controllers/operator_controller.go.
$ operator-sdk create api --group app --version v1alpha1 --kind Operator
Create Resource [y/n]
y
Create Controller [y/n]
y
Writing scaffold for you to edit...
api/v1alpha1/operator_types.go
controllers/operator_controller.go
...
Define your API for the operator custom resource by editing the Go type definitions at api/v1alpha1/operator_types.go
// OperatorSpec defines the desired state of Operator
type OperatorSpec struct {
// INSERT ADDITIONAL SPEC FIELDS - desired state of cluster
// Important: Run "make" to regenerate code after modifying this file
// Foo is an example field of Operator. Edit Operator_types.go to remove/update
Size int32 `json:"size"`
Image string `json:"image"`
Response string `json:"response"`
}
// OperatorStatus defines the observed state of Operator
type OperatorStatus struct {
// INSERT ADDITIONAL STATUS FIELD - define observed state of cluster
// Important: Run "make" to regenerate code after modifying this file
Nodes []string `json:"nodes"`
}
// Operator is the Schema for the operators API
// +kubebuilder:subresource:status
type Operator struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec OperatorSpec `json:"spec,omitempty"`
Status OperatorStatus `json:"status,omitempty"`
}
After modifying the _types.go file you always need to run the following command to update the generated code for that resource type:
$ make generate
/home/ubuntu/.go/bin/controller-gen object:headerFile="hack/boilerplate.go.txt" paths="./..."
- Generate Custom Resource Definition (CRD) manifests
In the previous step we defined the API with spec and status fields of the CRD manifests, which can be generated and updated with the following command:
$ make manifests
/home/ubuntu/.go/bin/controller-gen "crd:trivialVersions=true" rbac:roleName=manager-role webhook paths="./..." output:crd:artifacts:config=config/crd/bases
This makefile will invoke the controller-gen to generate the CRD manifests at config/crd/bases/app.helloworld.io_operators.yaml and below you see my custom resource example for the operator:
apiVersion: app.helloworld.io/v1alpha1
kind: Operator
metadata:
name: operator-sample
spec:
size: 1
response: "Hello, World!"
image: "ghcr.io/berndonline/k8s/go-helloworld:latest"
In the beginning when I created the API, the operator-sdk automatically created the controller file for me at controllers/operator_controller.go which we now start to modify and add the Go code. I will not go into every detail because the different resources you will create will all look very similar and repeat like you will see in example code. I will mainly focus on the Deployment for my Helloworld container image which I want to deploy using the operator.
Let’s start looking at the deploymentForOperator function which defines and returns the Kubernetes Deployment object. You see there that I invoke an imported Go packages like &appsv1.Deployment and the import is defined at the top of the controller file. You can find details about this in the Go Doc reference: godoc.org/k8s.io/api/apps/v1
// deploymentForOperator returns a operator Deployment object
func (r *OperatorReconciler) deploymentForOperator(m *appv1alpha1.Operator) *appsv1.Deployment {
ls := labelsForOperator(m.Name)
replicas := m.Spec.Size
dep := &appsv1.Deployment{
ObjectMeta: metav1.ObjectMeta{
Name: m.Name,
Namespace: m.Namespace,
},
Spec: appsv1.DeploymentSpec{
Replicas: &replicas,
Selector: &metav1.LabelSelector{
MatchLabels: ls,
},
Template: corev1.PodTemplateSpec{
ObjectMeta: metav1.ObjectMeta{
Labels: ls,
},
Spec: corev1.PodSpec{
Containers: []corev1.Container{{
Image: m.Spec.Image,
ImagePullPolicy: "Always",
Name: "helloworld",
Ports: []corev1.ContainerPort{{
ContainerPort: 8080,
Name: "operator",
}},
Env: []corev1.EnvVar{{
Name: "RESPONSE",
Value: m.Spec.Response,
}},
EnvFrom: []corev1.EnvFromSource{{
ConfigMapRef: &corev1.ConfigMapEnvSource{
LocalObjectReference: corev1.LocalObjectReference{
Name: m.Name,
},
},
}},
VolumeMounts: []corev1.VolumeMount{{
Name: m.Name,
ReadOnly: true,
MountPath: "/helloworld/",
}},
}},
Volumes: []corev1.Volume{{
Name: m.Name,
VolumeSource: corev1.VolumeSource{
ConfigMap: &corev1.ConfigMapVolumeSource{
LocalObjectReference: corev1.LocalObjectReference{
Name: m.Name,
},
},
},
}},
},
},
},
}
// Set Operator instance as the owner and controller
ctrl.SetControllerReference(m, dep, r.Scheme)
return dep
}
We have defined the deploymentForOperator function and now we can look into the Reconcile function and add the step to check if the deployment already exists and, if not, to create the new deployment:
// Check if the deployment already exists, if not create a new one
found := &appsv1.Deployment{}
err = r.Get(ctx, types.NamespacedName{Name: operator.Name, Namespace: operator.Namespace}, found)
if err != nil && errors.IsNotFound(err) {
// Define a new deployment
dep := r.deploymentForOperator(operator)
log.Info("Creating a new Deployment", "Deployment.Namespace", dep.Namespace, "Deployment.Name", dep.Name)
err = r.Create(ctx, dep)
if err != nil {
log.Error(err, "Failed to create new Deployment", "Deployment.Namespace", dep.Namespace, "Deployment.Name", dep.Name)
return ctrl.Result{}, err
}
// Deployment created successfully - return and requeue
return ctrl.Result{Requeue: true}, nil
} else if err != nil {
log.Error(err, "Failed to get Deployment")
return ctrl.Result{}, err
}
Unfortunately this isn’t enough because this will only check if the deployment exists or not and create a new deployment, but it will not update the deployment if the custom resource is changed.
We need to add two more steps to check if the created Deployment Spec.Template matches the Spec.Template from the deploymentForOperator function and the Deployment Spec.Replicas the defined size from the custom resource. I will make use of the defined variable found := &appsv1.Deployment{} from the previous step when I checked if the deployment exists.
// Check if the deployment Spec.Template, matches the found Spec.Template
deploy := r.deploymentForOperator(operator)
if !equality.Semantic.DeepDerivative(deploy.Spec.Template, found.Spec.Template) {
found = deploy
log.Info("Updating Deployment", "Deployment.Namespace", found.Namespace, "Deployment.Name", found.Name)
err := r.Update(ctx, found)
if err != nil {
log.Error(err, "Failed to update Deployment", "Deployment.Namespace", found.Namespace, "Deployment.Name", found.Name)
return ctrl.Result{}, err
}
return ctrl.Result{Requeue: true}, nil
}
// Ensure the deployment size is the same as the spec
size := operator.Spec.Size
if *found.Spec.Replicas != size {
found.Spec.Replicas = &size
err = r.Update(ctx, found)
if err != nil {
log.Error(err, "Failed to update Deployment", "Deployment.Namespace", found.Namespace, "Deployment.Name", found.Name)
return ctrl.Result{}, err
}
// Spec updated - return and requeue
return ctrl.Result{Requeue: true}, nil
}
The SetupWithManager() function in controllers/operator_controller.go specifies how the controller is built to watch a custom resource and other resources that are owned and managed by that controller.
func (r *OperatorReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&appv1alpha1.Operator{}).
Owns(&appsv1.Deployment{}).
Owns(&corev1.ConfigMap{}).
Owns(&corev1.Service{}).
Owns(&networkingv1beta1.Ingress{}).
Complete(r)
}
Basically that’s all I need to write for the controller to deploy my Helloworld container image using an Kubernetes operator. In my code example you will find that I also create a Kubernetes Service, Ingress and ConfigMap but you see that this mostly repeats what I have done with the Deployment object.
Before we can start running the operator, we need to define the RBAC permissions the controller needs to interact with the resources it manages otherwise your controller will not work. These are specified via [RBAC markers] like these:
// +kubebuilder:rbac:groups=app.helloworld.io,resources=operators,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=app.helloworld.io,resources=operators/status,verbs=get;update;patch
// +kubebuilder:rbac:groups=app.helloworld.io,resources=operators/finalizers,verbs=update
// +kubebuilder:rbac:groups=apps,resources=deployments,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=core,resources=services,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=core,resources=configmaps,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=networking.k8s.io,resources=ingresses,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=core,resources=pods,verbs=get;list;watch
The ClusterRole manifest at config/rbac/role.yaml is generated from the above markers via controller-gen with the following command:
$ make manifests
/home/ubuntu/.go/bin/controller-gen "crd:trivialVersions=true" rbac:roleName=manager-role webhook paths="./..." output:crd:artifacts:config=config/crd/bases
We need a Kubernetes cluster and admin privileges to run the operator. I will use Kind which will run a lightweight Kubernetes cluster in your local Docker engine, which is all I need to run and test my Helloworld operator:
$ ./scripts/create-kind-cluster.sh
Creating cluster "kind" ...
✓ Ensuring node image (kindest/node:v1.19.1) 🖼
✓ Preparing nodes 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
Set kubectl context to "kind-kind"
You can now use your cluster with:
kubectl cluster-info --context kind-kind
Have a question, bug, or feature request? Let us know! https://kind.sigs.k8s.io/#community 🙂
Before running the operator the custom resource Definition must be registered with the Kubernetes apiserver:
$ make install
/home/ubuntu/.go/bin/controller-gen "crd:trivialVersions=true" rbac:roleName=manager-role webhook paths="./..." output:crd:artifacts:config=config/crd/bases
/usr/bin/kustomize build config/crd | kubectl apply -f -
Warning: apiextensions.k8s.io/v1beta1 CustomResourceDefinition is deprecated in v1.16+, unavailable in v1.22+; use apiextensions.k8s.io/v1 CustomResourceDefinition
customresourcedefinition.apiextensions.k8s.io/operators.app.helloworld.io created
We can now run the operator locally on my workstation:
$ make run
/home/ubuntu/.go/bin/controller-gen object:headerFile="hack/boilerplate.go.txt" paths="./..."
go fmt ./...
go vet ./...
/home/ubuntu/.go/bin/controller-gen "crd:trivialVersions=true" rbac:roleName=manager-role webhook paths="./..." output:crd:artifacts:config=config/crd/bases
go run ./main.go
2020-11-22T18:12:49.023Z INFO controller-runtime.metrics metrics server is starting to listen {"addr": ":8080"}
2020-11-22T18:12:49.024Z INFO setup starting manager
2020-11-22T18:12:49.025Z INFO controller-runtime.manager starting metrics server {"path": "/metrics"}
2020-11-22T18:12:49.025Z INFO controller Starting EventSource {"reconcilerGroup": "app.helloworld.io", "reconcilerKind": "Operator", "controller": "operator", "source": "kind source: /, Kind="}
2020-11-22T18:12:49.126Z INFO controller Starting EventSource {"reconcilerGroup": "app.helloworld.io", "reconcilerKind": "Operator", "controller": "operator", "source": "kind source: /, Kind="}
2020-11-22T18:12:49.226Z INFO controller Starting EventSource {"reconcilerGroup": "app.helloworld.io", "reconcilerKind": "Operator", "controller": "operator", "source": "kind source: /, Kind="}
2020-11-22T18:12:49.327Z INFO controller Starting EventSource {"reconcilerGroup": "app.helloworld.io", "reconcilerKind": "Operator", "controller": "operator", "source": "kind source: /, Kind="}
2020-11-22T18:12:49.428Z INFO controller Starting EventSource {"reconcilerGroup": "app.helloworld.io", "reconcilerKind": "Operator", "controller": "operator", "source": "kind source: /, Kind="}
2020-11-22T18:12:49.528Z INFO controller Starting Controller {"reconcilerGroup": "app.helloworld.io", "reconcilerKind": "Operator", "controller": "operator"}
2020-11-22T18:12:49.528Z INFO controller Starting workers {"reconcilerGroup": "app.helloworld.io", "reconcilerKind": "Operator", "controller": "operator", "worker count": 1}
Let’s open a new terminal and apply the custom resource example:
$ kubectl apply -f config/samples/app_v1alpha1_operator.yaml
operator.app.helloworld.io/operator-sample created
Going back to the terminal where the operator is running, you see the log messages that it invoke the different functions to deploy the defined resource objects:
2020-11-22T18:15:30.412Z INFO controllers.Operator Creating a new Deployment {"operator": "default/operator-sample", "Deployment.Namespace": "default", "Deployment.Name": "operator-sample"}
2020-11-22T18:15:30.446Z INFO controllers.Operator Creating a new ConfigMap {"operator": "default/operator-sample", "ConfigMap.Namespace": "default", "ConfigMap.Name": "operator-sample"}
2020-11-22T18:15:30.453Z INFO controllers.Operator Creating a new Service {"operator": "default/operator-sample", "Service.Namespace": "default", "Service.Name": "operator-sample"}
2020-11-22T18:15:30.470Z INFO controllers.Operator Creating a new Ingress {"operator": "default/operator-sample", "Ingress.Namespace": "default", "Ingress.Name": "operator-sample"}
2020-11-22T18:15:30.927Z DEBUG controller Successfully Reconciled {"reconcilerGroup": "app.helloworld.io", "reconcilerKind": "Operator", "controller": "operator", "name": "operator-sample", "namespace": "default"}
2020-11-22T18:15:30.927Z DEBUG controller Successfully Reconciled {"reconcilerGroup": "app.helloworld.io", "reconcilerKind": "Operator", "controller": "operator", "name": "operator-sample", "namespace": "default"}
2020-11-22T18:15:33.776Z DEBUG controller Successfully Reconciled {"reconcilerGroup": "app.helloworld.io", "reconcilerKind": "Operator", "controller": "operator", "name": "operator-sample", "namespace": "default"}
2020-11-22T18:15:35.181Z DEBUG controller Successfully Reconciled {"reconcilerGroup": "app.helloworld.io", "reconcilerKind": "Operator", "controller": "operator", "name": "operator-sample", "namespace": "default"}
In the default namespace where I applied the custom resource you will see the deployed resources by the operator:
$ kubectl get operators.app.helloworld.io
NAME AGE
operator-sample 6m11s
$ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/operator-sample-767897c4b9-8zwsd 1/1 Running 0 2m59s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 443/TCP 29m
service/operator-sample ClusterIP 10.96.199.188 8080/TCP 2m59s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/operator-sample 1/1 1 1 2m59s
NAME DESIRED CURRENT READY AGE
replicaset.apps/operator-sample-767897c4b9 1 1 1 2m59s
There is not much else to do other than to build the operator image and push to an image registry so that I can run the operator on a Kubernetes cluster.
$ make docker-build IMG=ghcr.io/berndonline/k8s/helloworld-operator:latest
$ make docker-push IMG=ghcr.io/berndonline/k8s/helloworld-operator:latest
$ kustomize build config/default | kubectl apply -f -
I hope this article is useful for getting you started on writing your own Kubernetes operator in Go.
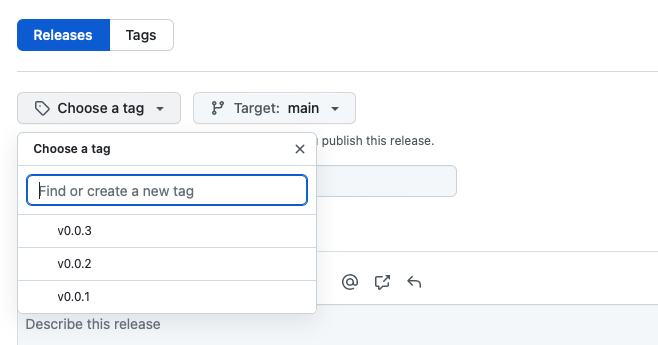
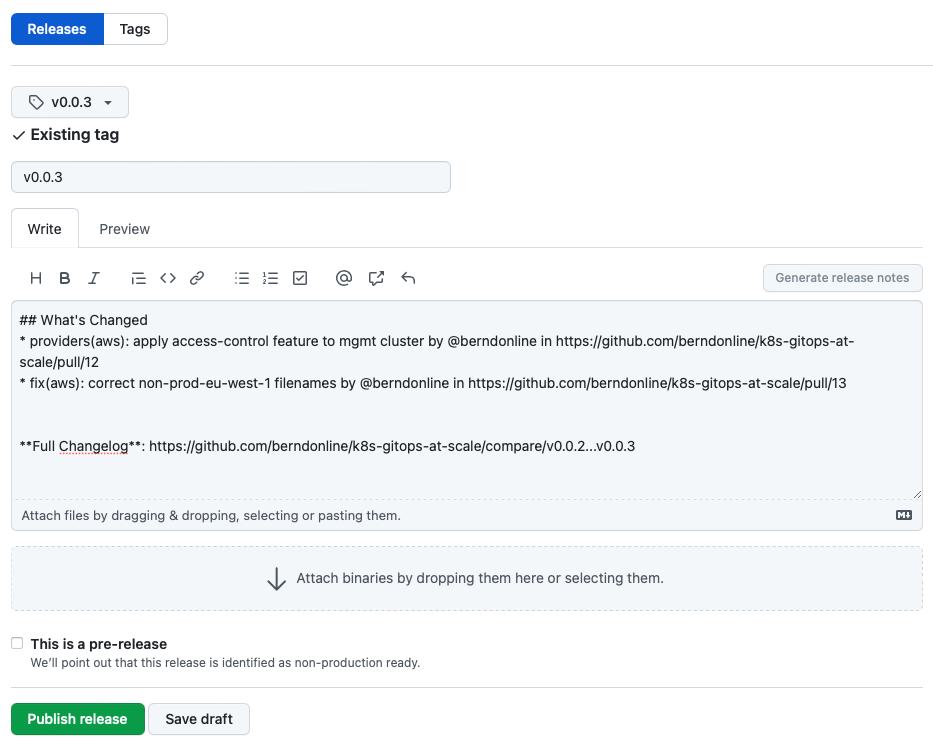
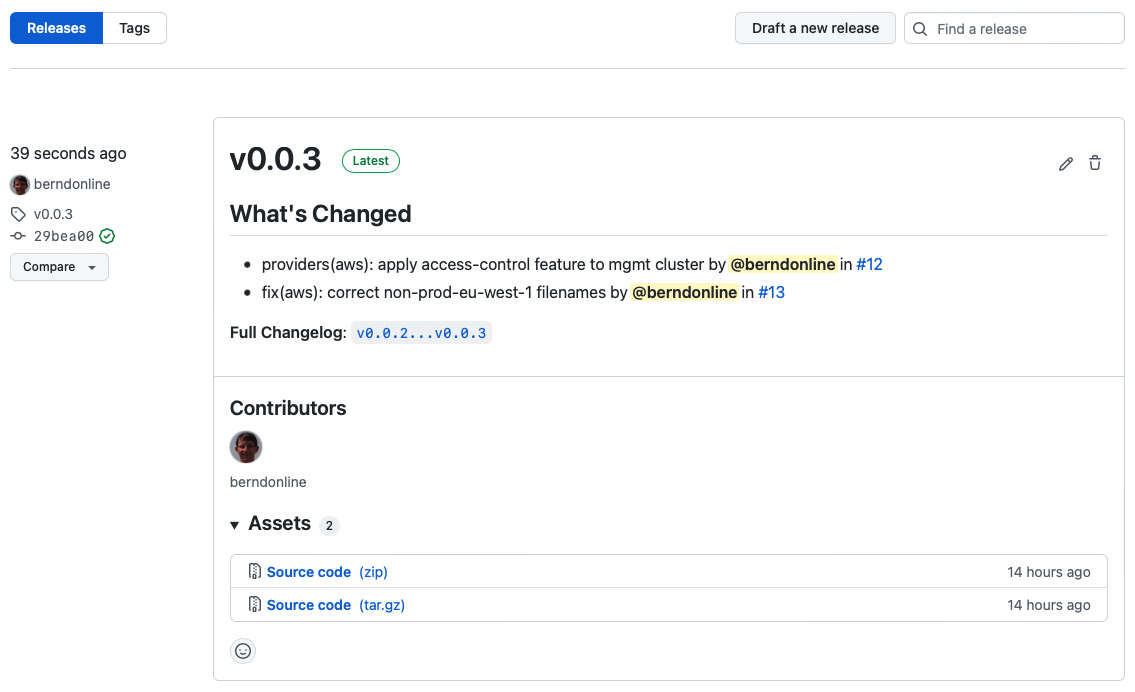
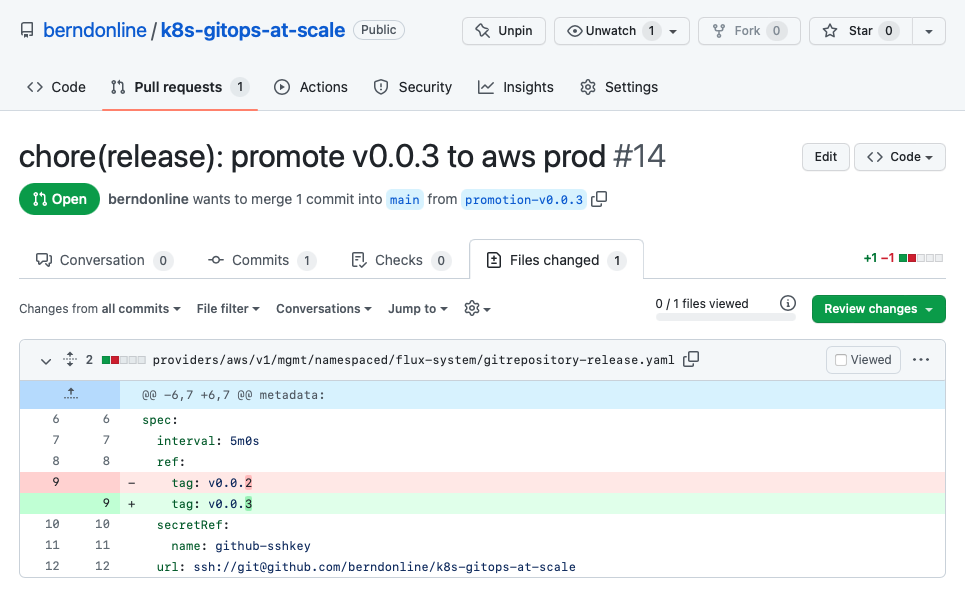
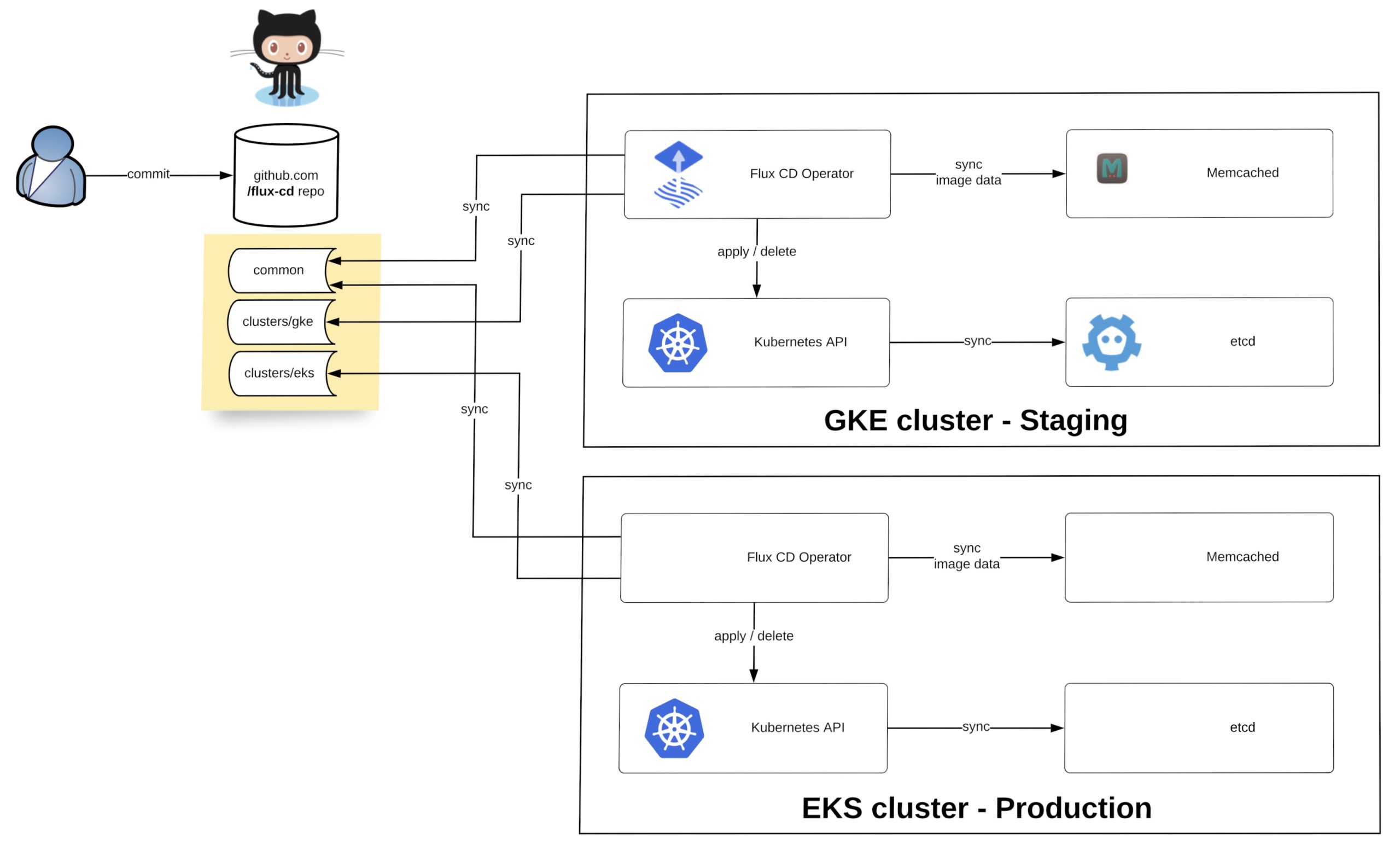
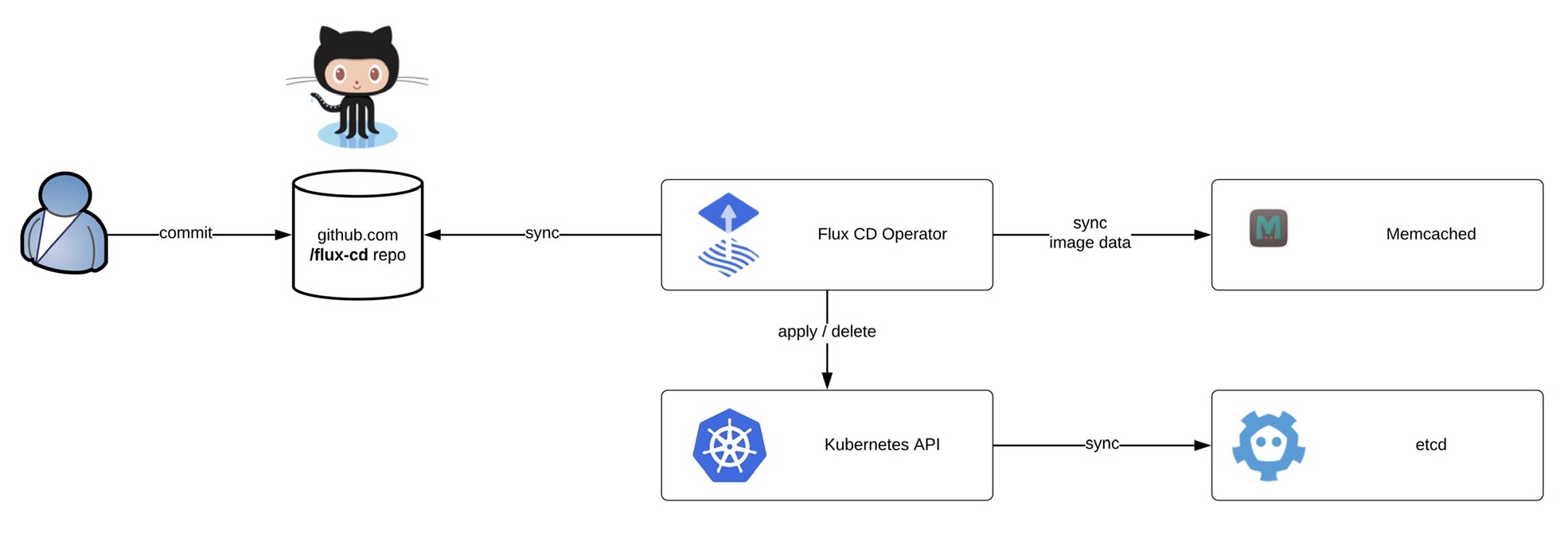 Before we start deploying the operator we need to install the fluxctl command-line utility and create the namespace:
Before we start deploying the operator we need to install the fluxctl command-line utility and create the namespace: Now you are ready to synchronise the Flux operator with the repository. By default Flux automatically synchronises every 5 minutes to apply configuration changes:
Now you are ready to synchronise the Flux operator with the repository. By default Flux automatically synchronises every 5 minutes to apply configuration changes: