I had to troubleshoot an interesting issue with OpenShift Infra nodes suddenly going into “Not Ready” state during an OpenShift upgrade or not registering on Master nodes after a re-install of OpenShift cluster. On the Infra nodes Avi Service Engines were running for ingress traffic. The problem was not very obvious and RedHat and Avi Networks were not able to identify the issue.
Here the output of oc get nodes:
[root@master01 ~]# oc get nodes -o wide --show-labels | grep 'region=infra'
infra01 NotReady 1d v1.7.6+a08f5eeb62 Red Hat Enterprise Linux Server 7.6 (Maipo) 3.10.0-693.11.6.el7.x86_64 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/instance-type=Standard_D8_v3,beta.kubernetes.io/os=linux,failure-domain.beta.kubernetes.io/region=uksouth,failure-domain.beta.kubernetes.io/zone=1,kubernetes.io/hostname=infra01,logging-infra-fluentd=true,purpose=infra,region=infra,zone=1
infra02 NotReady 1d v1.7.6+a08f5eeb62 Red Hat Enterprise Linux Server 7.6 (Maipo) 3.10.0-693.11.6.el7.x86_64 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/instance-type=Standard_D8_v3,beta.kubernetes.io/os=linux,failure-domain.beta.kubernetes.io/region=uksouth,failure-domain.beta.kubernetes.io/zone=1,kubernetes.io/hostname=infra02,logging-infra-fluentd=true,purpose=infra,region=infra,zone=0
infra03 NotReady 1d v1.7.6+a08f5eeb62 Red Hat Enterprise Linux Server 7.6 (Maipo) 3.10.0-693.11.6.el7.x86_64 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/instance-type=Standard_D8_v3,beta.kubernetes.io/os=linux,failure-domain.beta.kubernetes.io/region=uksouth,failure-domain.beta.kubernetes.io/zone=0,kubernetes.io/hostname=infra03,logging-infra-fluentd=true,purpose=infra,region=infra,zone=2
[root@master01 ~]#
On the Infra node itself you could see that the atomic node service had successfully started but I saw a very strange error message from the kubelet not being able to synchronise the pod:
I1206 14:52:28.115735 21690 cloud_request_manager.go:89] Requesting node addresses from cloud provider for node "infra01"
I1206 14:52:28.170366 21690 cloud_request_manager.go:108] Node addresses from cloud provider for node "infra01" collected
E1206 14:52:28.533560 21690 eviction_manager.go:238] eviction manager: unexpected err: failed GetNode: node 'infra01' not found
I1206 14:52:32.840769 21690 kubelet.go:1808] skipping pod synchronization - [Kubelet failed to get node info: failed to get zone from cloud provider: Get http://169.254.169.254/metadata/v1/InstanceInfo: dial tcp 169.254.169.254:80: getsockopt: no route to host]
I1206 14:52:37.841235 21690 kubelet.go:1808] skipping pod synchronization - [Kubelet failed to get node info: failed to get zone from cloud provider: Get http://169.254.169.254/metadata/v1/InstanceInfo: dial tcp 169.254.169.254:80: getsockopt: no route to host]
I1206 14:52:38.170604 21690 cloud_request_manager.go:89] Requesting node addresses from cloud provider for node "infra01"
I1206 14:52:38.222439 21690 cloud_request_manager.go:108] Node addresses from cloud provider for node "infra01" collected
E1206 14:52:38.545991 21690 eviction_manager.go:238] eviction manager: unexpected err: failed GetNode: node 'infra01' not found
I1206 14:52:42.841547 21690 kubelet.go:1808] skipping pod synchronization - [Kubelet failed to get node info: failed to get zone from cloud provider: Get http://169.254.169.254/metadata/v1/InstanceInfo: dial tcp 169.254.169.254:80: getsockopt: no route to host]
I1206 14:52:47.841819 21690 kubelet.go:1808] skipping pod synchronization - [Kubelet failed to get node info: failed to get zone from cloud provider: Get http://169.254.169.254/metadata/v1/InstanceInfo: dial tcp 169.254.169.254:80: getsockopt: no route to host]
Even stranger is that the kubelet was not able to get the metadata information of the Azure Cloud provider with the fault domain in which the instance is running.
About the “no route to host” error I thought this must be a network issue and that I could reproduce this with a simple curl command:
[root@infra01 ~]# curl -v http://169.254.169.254/metadata/v1/InstanceInfo
* About to connect() to 169.254.169.254 port 80 (#0)
* Trying 169.254.169.254...
* No route to host
* Failed connect to 169.254.169.254:80; No route to host
* Closing connection 0
curl: (7) Failed connect to 169.254.169.254:80; No route to host
[root@infra01 ~]#
The routing table on the node looked fine and theoretically forwarded the traffic to the default gateway in the subnet.
[root@infra01 ~]# ip route show
default via 10.1.1.1 dev eth0
10.1.1.0/27 dev eth0 proto kernel scope link src 10.1.1.10
10.128.0.0/15 dev tun0 scope link
10.128.0.0/15 dev tun0
168.63.129.16 via 10.1.1.1 dev eth0 proto static
169.254.0.0/16 dev eth0 scope link metric 1002
169.254.169.254 via 10.1.1.1 dev eth0 proto static
172.17.0.0/16 via 172.17.0.1 dev docker0
172.18.0.0/16 dev bravi proto kernel scope link src 172.18.0.1
[root@infra01 ~]#
What was a bit strange when I used tracepath was that the packets weren’t forwarded to the default gateway but instead forwarded to the node itself:
[root@infra01 ~]# tracepath 169.254.169.254
1?: [LOCALHOST] pmtu 1500
1: infra01 3006.801ms !H
Resume: pmtu 1500
Same with traceroute or ping output:
[root@infra01 ~]# traceroute 169.254.169.254
traceroute to 169.254.169.254 (169.254.169.254), 30 hops max, 60 byte packets
1 infra01 (172.18.0.1) 1178.146 ms !H 1178.104 ms !H 1178.057 ms !H
[root@infra01 ~]# ping 169.254.169.254
PING 169.254.169.254 (169.254.169.254) 56(84) bytes of data.
From 172.18.0.1 icmp_seq=1 Destination Host Unreachable
From 172.18.0.1 icmp_seq=2 Destination Host Unreachable
From 172.18.0.1 icmp_seq=3 Destination Host Unreachable
From 172.18.0.1 icmp_seq=4 Destination Host Unreachable
^C
--- 169.254.169.254 ping statistics ---
5 packets transmitted, 0 received, +4 errors, 100% packet loss, time 4000ms
pipe 4
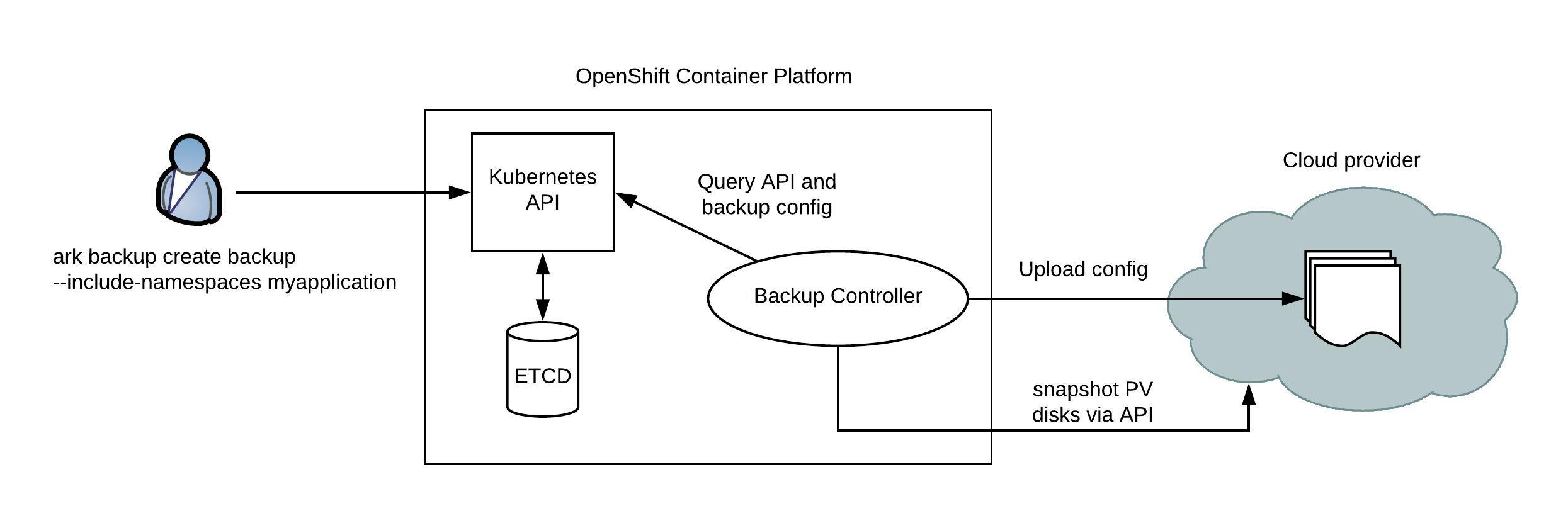
What was very obvious was that the packets were forwarded to the bravi bridge 172.18.0.0/16 which is owned by the Avi Service Engine on the Infra node:
...
44: bravi: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN qlen 1000
link/ether 00:00:00:00:00:01 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.1/16 scope global bravi
valid_lft forever preferred_lft forever
inet6 fe80::200:ff:fe00:1/64 scope link
valid_lft forever preferred_lft forever
45: bravi-tap: <BROADCAST,MULTICAST> mtu 1500 qdisc noop master bravi state DOWN qlen 1000
link/ether 00:00:00:00:00:01 brd ff:ff:ff:ff:ff:ff
...
Here is the article about how Avi SE are integrated into the OpenShift SDN. Avi uses PBR (policy based routing) to forward external ingress traffic to the Service Engine.
I have turned off the bravi bridge because PBR could be bypassing the routing table for traffic to the 169.254.169.254.
[root@infra01 ~]# ip link set bravi down
Traffic is now exiting the Infra node:
[root@infra01 ~]# traceroute 169.254.169.254
traceroute to 169.254.169.254 (169.254.169.254), 30 hops max, 60 byte packets
1 * * *
2 * * *
3 * * *
4 * * *
5 * * *
6 *^C
[root@infra01 ~]#
And the Infra node was able to collect metadata information:
[root@infra01 ~]# curl -v http://169.254.169.254/metadata/v1/InstanceInfo
* About to connect() to 169.254.169.254 port 80 (#0)
* Trying 169.254.169.254...
* Connected to 169.254.169.254 (169.254.169.254) port 80 (#0)
GET /metadata/v1/InstanceInfo HTTP/1.1
User-Agent: curl/7.29.0
Host: 169.254.169.254
Accept: */*
< HTTP/1.1 200 OK
< Content-Type: text/json; charset=utf-8
< Server: Microsoft-IIS/10.0
< Date: Thu, 06 Dec 2018 13:53:16 GMT
< Content-Length: 43
<
* Connection #0 to host 169.254.169.254 left intact
{"ID":"_infra01","UD":"4","FD":"0"}
[root@infra01 ~]#
Simple restart of the atomic node service to trigger the master registration:
[root@infra01 ~]# systemctl restart atomic-openshift-node
The logs showed that the kubelet successfully got zone information
Dec 07 16:03:21 infra01 atomic-openshift-node[36736]: I1207 16:03:21.341611 36813 kubelet_node_status.go:270] Setting node annotation to enable volume controller attach/detach
Dec 07 16:03:21 infra01 atomic-openshift-node[36736]: I1207 16:03:21.414847 36813 kubelet_node_status.go:326] Adding node label from cloud provider: beta.kubernetes.io/instance-type=Standard_D8_
Dec 07 16:03:21 infra01 atomic-openshift-node[36736]: I1207 16:03:21.414881 36813 kubelet_node_status.go:337] Adding node label from cloud provider: failure-domain.beta.kubernetes.io/zone=0
Dec 07 16:03:21 infra01 atomic-openshift-node[36736]: I1207 16:03:21.414890 36813 kubelet_node_status.go:341] Adding node label from cloud provider: failure-domain.beta.kubernetes.io/region=ukso
Dec 07 16:03:21 infra01 atomic-openshift-node[36736]: I1207 16:03:21.414966 36813 kubelet_node_status.go:488] Using Node Hostname from cloudprovider: "infra01"
Dec 07 16:03:21 infra01 atomic-openshift-node[36736]: I1207 16:03:21.420823 36813 kubelet_node_status.go:437] Recording NodeHasSufficientDisk event message for node infra01
Dec 07 16:03:21 infra01 atomic-openshift-node[36736]: I1207 16:03:21.420907 36813 kubelet_node_status.go:437] Recording NodeHasSufficientMemory event message for node infra01
Dec 07 16:03:21 infra01 atomic-openshift-node[36736]: I1207 16:03:21.423139 36813 kubelet_node_status.go:437] Recording NodeHasNoDiskPressure event message for node infra01
Dec 07 16:03:21 infra01 atomic-openshift-node[36736]: I1207 16:03:21.423235 36813 kubelet_node_status.go:82] Attempting to register node infra01
Dec 07 16:03:21 infra01 atomic-openshift-node[36736]: I1207 16:03:21.435412 36813 kubelet_node_status.go:85] Successfully registered node infra01
Dec 07 16:03:21 infra01 atomic-openshift-node[36736]: I1207 16:03:21.437308 36813 kubelet_node_status.go:488] Using Node Hostname from cloudprovider: "infra01"
Dec 07 16:03:21 infra01 atomic-openshift-node[36736]: I1207 16:03:21.441482 36813 manager.go:311] Recovery completed
The Infra node successfully registered again the OpenShift master and the node went into “Ready”:
[root@master01 ~]# oc get nodes -o wide --show-labels | grep 'region=infra'
infra01 Ready 40s v1.7.6+a08f5eeb62 Red Hat Enterprise Linux Server 7.6 (Maipo) 3.10.0-693.11.6.el7.x86_64 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/instance-type=Standard_D8_v3,beta.kubernetes.io/os=linux,failure-domain.beta.kubernetes.io/region=uksouth,failure-domain.beta.kubernetes.io/zone=0,kubernetes.io/hostname=infra01,logging-infra-fluentd=true,purpose=infra,region=infra,zone=1
infra02 Ready 1d v1.7.6+a08f5eeb62 Red Hat Enterprise Linux Server 7.6 (Maipo) 3.10.0-693.11.6.el7.x86_64 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/instance-type=Standard_D8_v3,beta.kubernetes.io/os=linux,failure-domain.beta.kubernetes.io/region=uksouth,failure-domain.beta.kubernetes.io/zone=1,kubernetes.io/hostname=infra02,logging-infra-fluentd=true,purpose=infra,region=infra,zone=0
infra03 Ready 1d v1.7.6+a08f5eeb62 Red Hat Enterprise Linux Server 7.6 (Maipo) 3.10.0-693.11.6.el7.x86_64 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/instance-type=Standard_D8_v3,beta.kubernetes.io/os=linux,failure-domain.beta.kubernetes.io/region=uksouth,failure-domain.beta.kubernetes.io/zone=0,kubernetes.io/hostname=infra03,logging-infra-fluentd=true,purpose=infra,region=infra,zone=2
[root@master01 ~]#
In the end, the root cause was the Avi East West subnet range which was set to 169.254.0.0/16 on the Avi controller nodes. Even the East West communication was deactivated on Avi, because kube_proxy was used, which made the Avi controller configure PBR on the bravi bridge for the 169.254.0.0/16 subnet range. This subnet range was previously used on all the on-prem datacenters and never caused issues since moving to cloud because the 169.254.169.254 is commonly used on cloud provider for instances to collect metadata information.