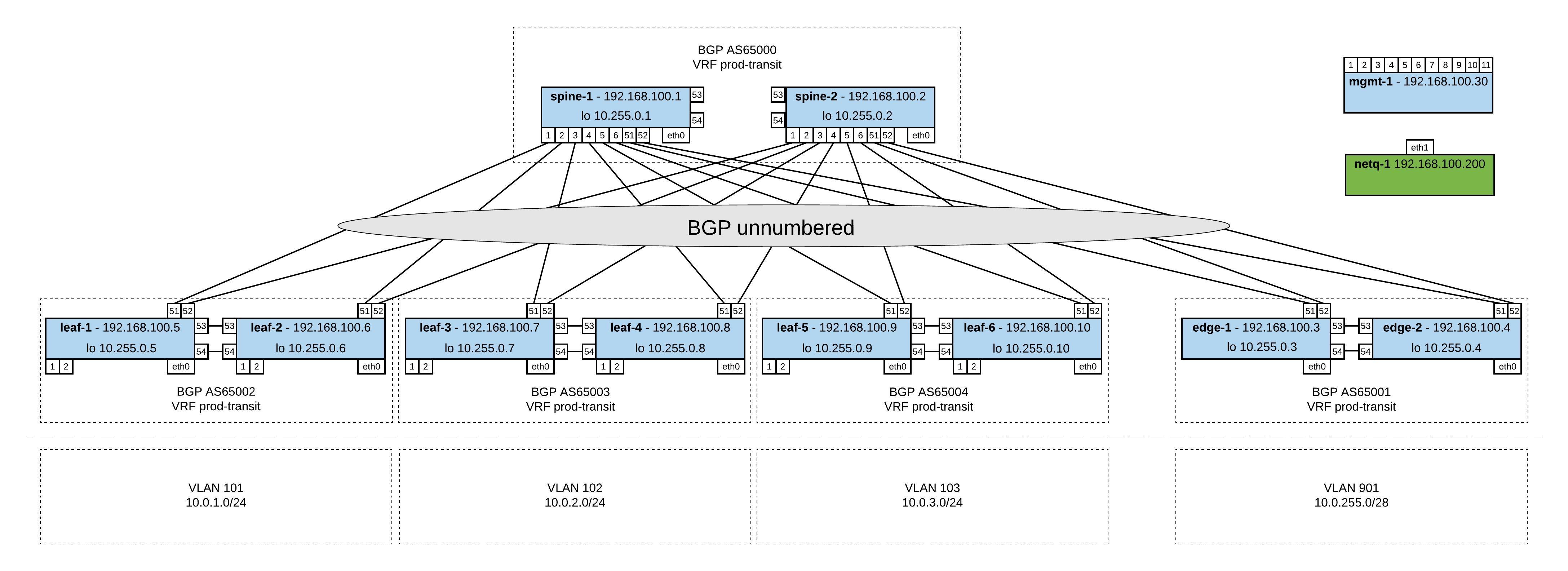
Here a new post about Cumulus NetQ, I build a small Ansible playbook to validate the state of MLAG within a Cumulus Linux fabric using automation.
In this case I use the command “netq check clag json” to check for nodes in failed or warning state. This example can be used when doing automated changes to MLAG and to validate the configuration afterwards, or as a pre-check before I execute the main playbook.
---
- hosts: spine leaf
gather_facts: False
user: cumulus
tasks:
- name: Gather Clag info in JSON
command: netq check clag json
register: result
run_once: true
failed_when: "'ERROR' in result.stdout"
- name: stdout string into json
set_fact: json_output="{{result.stdout | from_json }}"
run_once: true
- name: output of json_output variable
debug:
var: json_output
run_once: true
- name: check failed clag members
debug: msg="Check failed clag members"
when: json_output["failedNodes"]|length == 0
run_once: true
- name: clag members status failed
fail: msg="Device {{item['node']}}, Why node is in failed state? {{item['reason']}}"
with_items: "{{json_output['failedNodes']}}"
run_once: true
- name: clag members status warning
fail: msg="Device {{item['node']}}, Why node is in warning state? {{item['reason']}}"
when: json_output["warningNodes"] is defined
with_items: "{{json_output['warningNodes']}}"
run_once: true
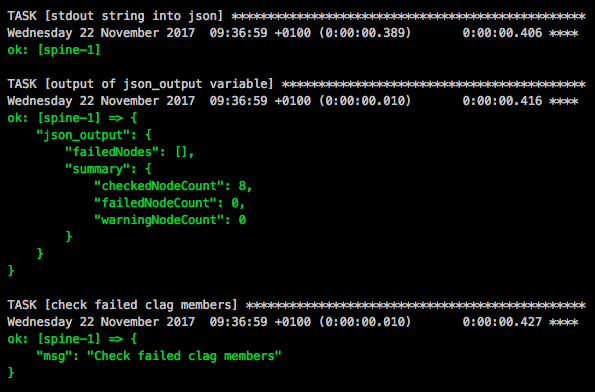
Here the output when MLAG is healthy:
PLAY [spine leaf] *********************************************************************************************************************************************************************************************************************
TASK [Gather Clag info in JSON] *******************************************************************************************************************************************************************************************************
Friday 20 October 2017 17:56:35 +0200 (0:00:00.017) 0:00:00.017 ********
changed: [spine-1]
TASK [stdout string into json] ********************************************************************************************************************************************************************************************************
Friday 20 October 2017 17:56:35 +0200 (0:00:00.325) 0:00:00.343 ********
ok: [spine-1]
TASK [output of json_output variable] *************************************************************************************************************************************************************************************************
Friday 20 October 2017 17:56:35 +0200 (0:00:00.010) 0:00:00.353 ********
ok: [spine-1] => {
"json_output": {
"failedNodes": [],
"summary": {
"checkedNodeCount": 4,
"failedNodeCount": 0,
"warningNodeCount": 0
}
}
}
TASK [check failed clag members] ******************************************************************************************************************************************************************************************************
Friday 20 October 2017 17:56:35 +0200 (0:00:00.010) 0:00:00.363 ********
ok: [spine-1] => {
"msg": "Check failed clag members"
}
TASK [clag members status failed] *****************************************************************************************************************************************************************************************************
Friday 20 October 2017 17:56:35 +0200 (0:00:00.011) 0:00:00.374 ********
TASK [clag members status warning] ****************************************************************************************************************************************************************************************************
Friday 20 October 2017 17:56:35 +0200 (0:00:00.007) 0:00:00.382 ********
skipping: [spine-1]
PLAY RECAP ****************************************************************************************************************************************************************************************************************************
spine-1 : ok=4 changed=1 unreachable=0 failed=0
Friday 20 October 2017 17:56:35 +0200 (0:00:00.008) 0:00:00.391 ********
===============================================================================
Gather Clag info in JSON ------------------------------------------------ 0.33s
check failed clag members ----------------------------------------------- 0.01s
stdout string into json ------------------------------------------------- 0.01s
output of json_output variable ------------------------------------------ 0.01s
clag members status warning --------------------------------------------- 0.01s
clag members status failed ---------------------------------------------- 0.01s
In the following example leaf-1 node is in warning state because of a missing “clagd-backup-ip“, another warning could be also a single attached bond interface:
PLAY [spine leaf] *********************************************************************************************************************************************************************************************************************
TASK [Gather Clag info in JSON] *******************************************************************************************************************************************************************************************************
Friday 20 October 2017 18:02:05 +0200 (0:00:00.016) 0:00:00.016 ********
changed: [spine-1]
TASK [stdout string into json] ********************************************************************************************************************************************************************************************************
Friday 20 October 2017 18:02:05 +0200 (0:00:00.225) 0:00:00.241 ********
ok: [spine-1]
TASK [output of json_output variable] *************************************************************************************************************************************************************************************************
Friday 20 October 2017 18:02:05 +0200 (0:00:00.010) 0:00:00.251 ********
ok: [spine-1] => {
"json_output": {
"failedNodes": [],
"summary": {
"checkedNodeCount": 4,
"failedNodeCount": 0,
"warningNodeCount": 1
},
"warningNodes": [
{
"node": "leaf-1",
"reason": "Backup IP Failed"
}
]
}
}
TASK [check failed clag members] ******************************************************************************************************************************************************************************************************
Friday 20 October 2017 18:02:05 +0200 (0:00:00.010) 0:00:00.261 ********
ok: [spine-1] => {
"msg": "Check failed clag members"
}
TASK [clag members status failed] *****************************************************************************************************************************************************************************************************
Friday 20 October 2017 18:02:05 +0200 (0:00:00.011) 0:00:00.273 ********
TASK [clag members status warning] ****************************************************************************************************************************************************************************************************
Friday 20 October 2017 18:02:05 +0200 (0:00:00.007) 0:00:00.281 ********
failed: [spine-1] (item={u'node': u'leaf-1', u'reason': u'Backup IP Failed'}) => {"failed": true, "item": {"node": "leaf-1", "reason": "Backup IP Failed"}, "msg": "Device leaf-1, Why node is in warning state? Backup IP Failed"}
NO MORE HOSTS LEFT ********************************************************************************************************************************************************************************************************************
to retry, use: --limit @/home/berndonline/cumulus-lab-vagrant/netq_check_clag.retry
PLAY RECAP ****************************************************************************************************************************************************************************************************************************
spine-1 : ok=4 changed=1 unreachable=0 failed=1
Friday 20 October 2017 18:02:05 +0200 (0:00:00.015) 0:00:00.297 ********
===============================================================================
Gather Clag info in JSON ------------------------------------------------ 0.23s
clag members status warning --------------------------------------------- 0.02s
check failed clag members ----------------------------------------------- 0.01s
output of json_output variable ------------------------------------------ 0.01s
stdout string into json ------------------------------------------------- 0.01s
clag members status failed ---------------------------------------------- 0.01s
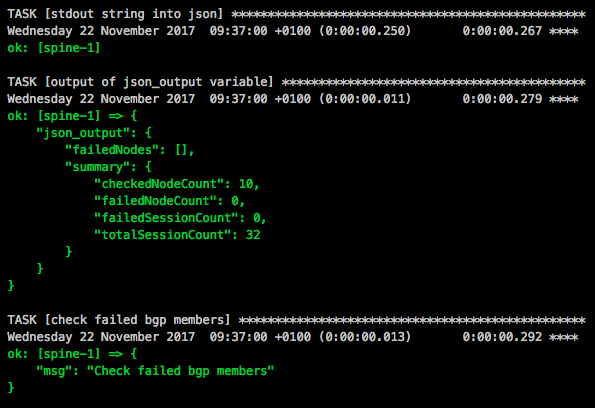
Another example is that NetQ reports about a problem that leaf-1 has no matching clagid on peer, in this case on leaf-2 the interface bond1 is missing in the configuration:
PLAY [spine leaf] ***********************************************************************************************************************************************************************************************************************
TASK [Gather Clag info in JSON] *********************************************************************************************************************************************************************************************************
Monday 23 October 2017 18:49:15 +0200 (0:00:00.016) 0:00:00.016 ********
changed: [spine-1]
TASK [stdout string into json] **********************************************************************************************************************************************************************************************************
Monday 23 October 2017 18:49:15 +0200 (0:00:00.223) 0:00:00.240 ********
ok: [spine-1]
TASK [output of json_output variable] ***************************************************************************************************************************************************************************************************
Monday 23 October 2017 18:49:15 +0200 (0:00:00.010) 0:00:00.250 ********
ok: [spine-1] => {
"json_output": {
"failedNodes": [
{
"node": "leaf-1",
"reason": "Conflicted Bonds: bond1:matching clagid not configured on peer"
}
],
"summary": {
"checkedNodeCount": 4,
"failedNodeCount": 1,
"warningNodeCount": 1
},
"warningNodes": [
{
"node": "leaf-1",
"reason": "Singly Attached Bonds: bond1"
}
]
}
}
TASK [check failed clag members] ********************************************************************************************************************************************************************************************************
Monday 23 October 2017 18:49:15 +0200 (0:00:00.010) 0:00:00.260 ********
skipping: [spine-1]
TASK [clag members status failed] *******************************************************************************************************************************************************************************************************
Monday 23 October 2017 18:49:15 +0200 (0:00:00.009) 0:00:00.269 ********
failed: [spine-1] (item={u'node': u'leaf-1', u'reason': u'Conflicted Bonds: bond1:matching clagid not configured on peer'}) => {"failed": true, "item": {"node": "leaf-1", "reason": "Conflicted Bonds: bond1:matching clagid not configured on peer"}, "msg": "Device leaf-1, Why node is in failed state? Conflicted Bonds: bond1:matching clagid not configured on peer"}
NO MORE HOSTS LEFT **********************************************************************************************************************************************************************************************************************
to retry, use: --limit @/home/berndonline/cumulus-lab-vagrant/netq_check_clag.retry
PLAY RECAP ******************************************************************************************************************************************************************************************************************************
spine-1 : ok=3 changed=1 unreachable=0 failed=1
Monday 23 October 2017 18:49:15 +0200 (0:00:00.014) 0:00:00.284 ********
===============================================================================
Gather Clag info in JSON ------------------------------------------------ 0.22s
clag members status failed ---------------------------------------------- 0.02s
stdout string into json ------------------------------------------------- 0.01s
output of json_output variable ------------------------------------------ 0.01s
check failed clag members ----------------------------------------------- 0.01s
This is just an example to show what possibilities I have with Cumulus NetQ when I use automation to validate my changes.
There are some information in the Cumulus NetQ documentation about, taking preventive steps with your network: https://docs.cumulusnetworks.com/display/NETQ/Taking+Preventative+Steps+with+Your+Network