I was using GNS3 for quite some time but it was not very flexible if you quickly wanted to test something and even more complicated if you used a different computer or shared your projects.
I spend some time with Vagrant to build a virtual Cumulus Linux lab environment which can run basically on every computer. Simulating network environments is the future when you want to test and validate your automation scripts.
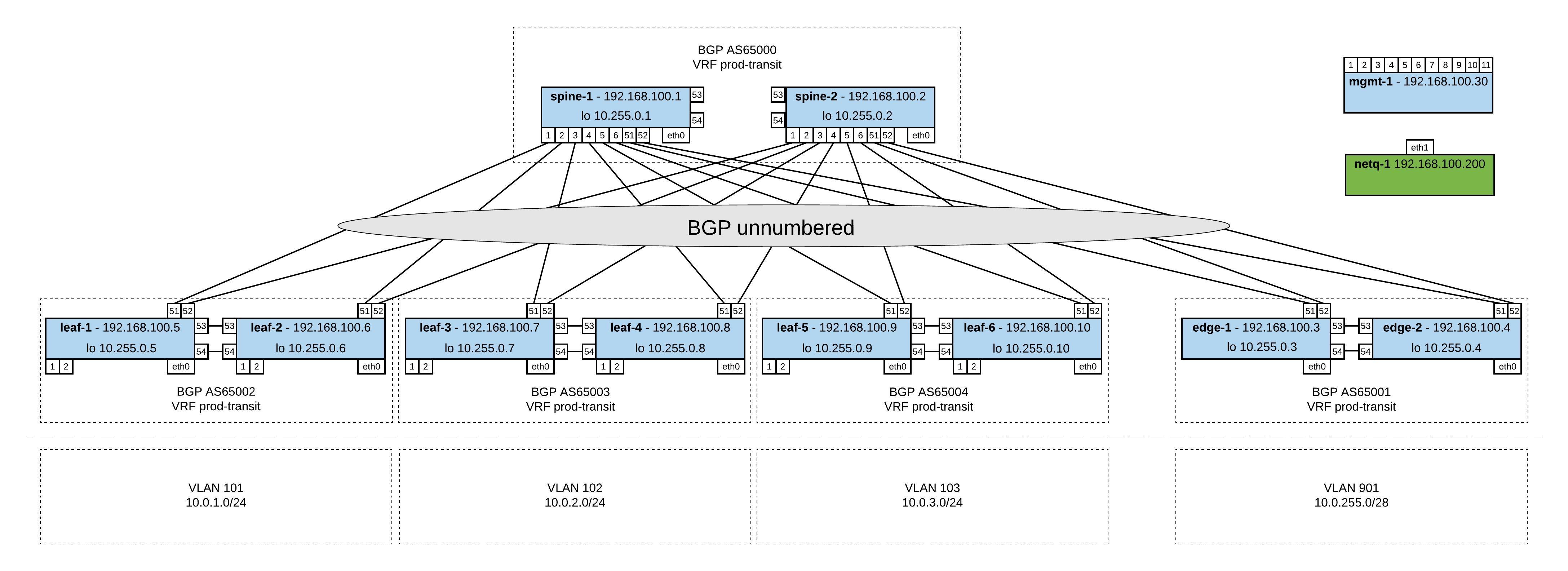
My lab diagram:
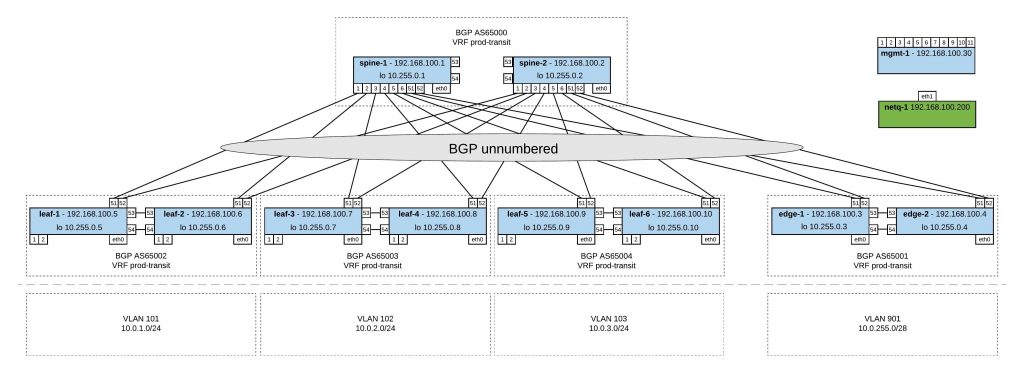
I created different topology.dot files and used the Cumulus topology converter on Github to create my lab with Virtualbox or Libvirt (KVM). I did some modification to the initialise scripts for the switches and the management server. Everything you find in my Github repo https://github.com/berndonline/cumulus-lab-vagrant.
The topology file basically defines your network and the converter creates the Vagrantfile.
In the management topology file you have all servers (incl. management) like in the network diagram above. The Cumulus switches you can only access via the management server.
Very similar to the topology-mgmt.dot but in this one the management server is running Cumulus NetQ which you need to first import into your Vagrant. Here the link to the Cumulus NetQ demo on Github.
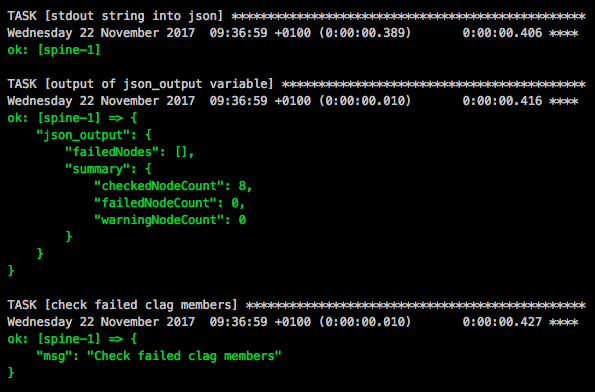
In this topology file you find a basic staging lab without servers where you can access the Cumulus switches directly via their Vagrant IP. I mainly use this to quickly test something like updating Cumulus switches or validating Ansible playbooks.
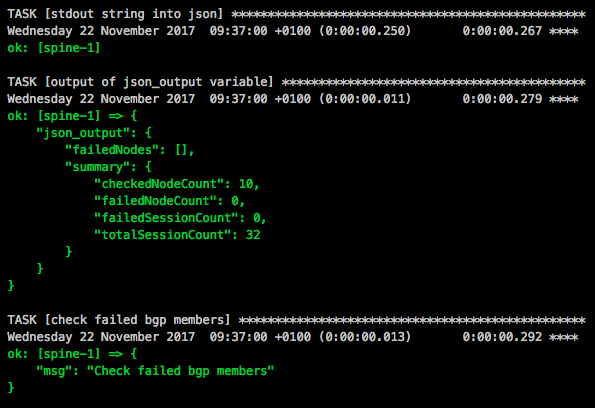
In this topology file you find a basic production lab where you can access the Cumulus switches directly via their Vagrant IP and have Cumulus NetQ as management server.
Basically to convert a topology into a Vagrantfile you just need to run the following command:
python topology_converter.py topology-staging.dot -p libvirt --ansible-hostfile
I use KVM in my example and want that Vagrant creates an Ansible inventory file and run playbooks directly agains the switches.
Check the status of the vagrant environment:
berndonline@lab:~/cumulus-lab-vagrant$ vagrant status
Current machine states:
spine-1 not created (libvirt)
spine-2 not created (libvirt)
leaf-1 not created (libvirt)
leaf-3 not created (libvirt)
leaf-2 not created (libvirt)
leaf-4 not created (libvirt)
mgmt-1 not created (libvirt)
edge-2 not created (libvirt)
edge-1 not created (libvirt)
This environment represents multiple VMs. The VMs are all listed
above with their current state. For more information about a specific
VM, run `vagrant status NAME`.
berndonline@lab:~/cumulus-lab-vagrant$
To start the devices run:
vagrant up
If you use the topology files with management server you need to start first the management server and then the management switch before you boot the rest of the switches:
vagrant up mgmt-server
vagrant up mgmt-1
vagrant up
The switches will pull some part of their configuration from the management server.
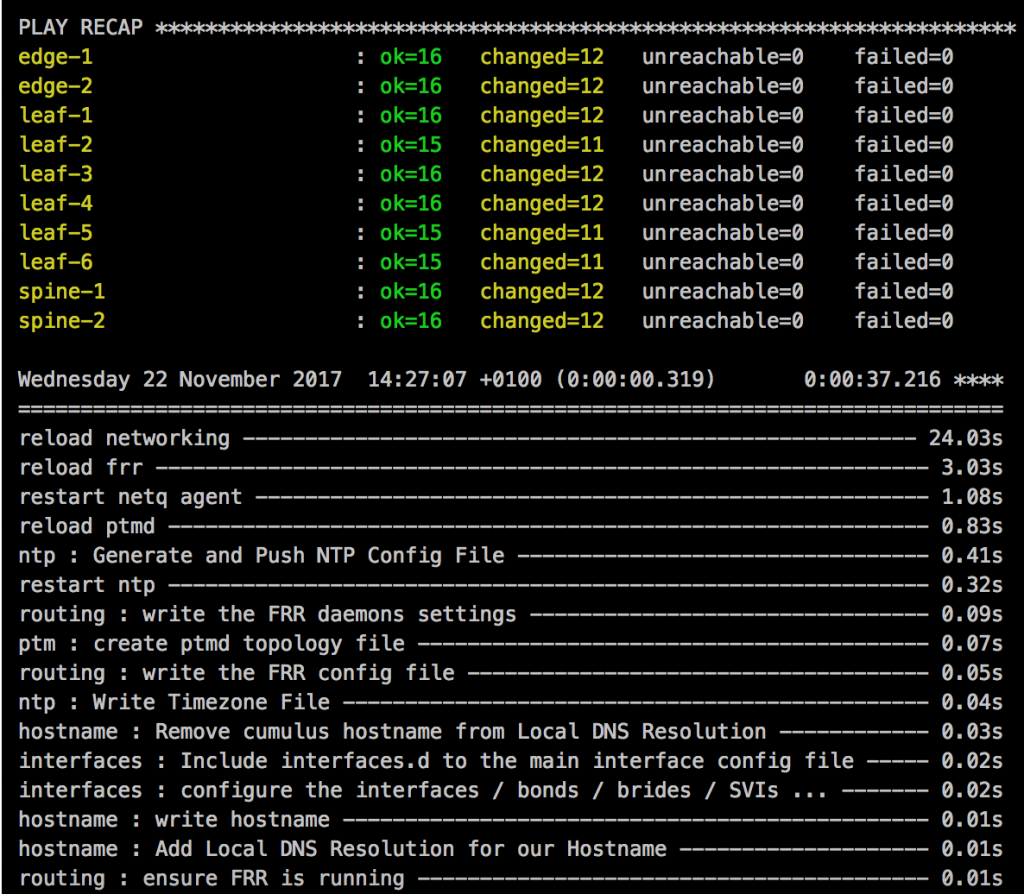
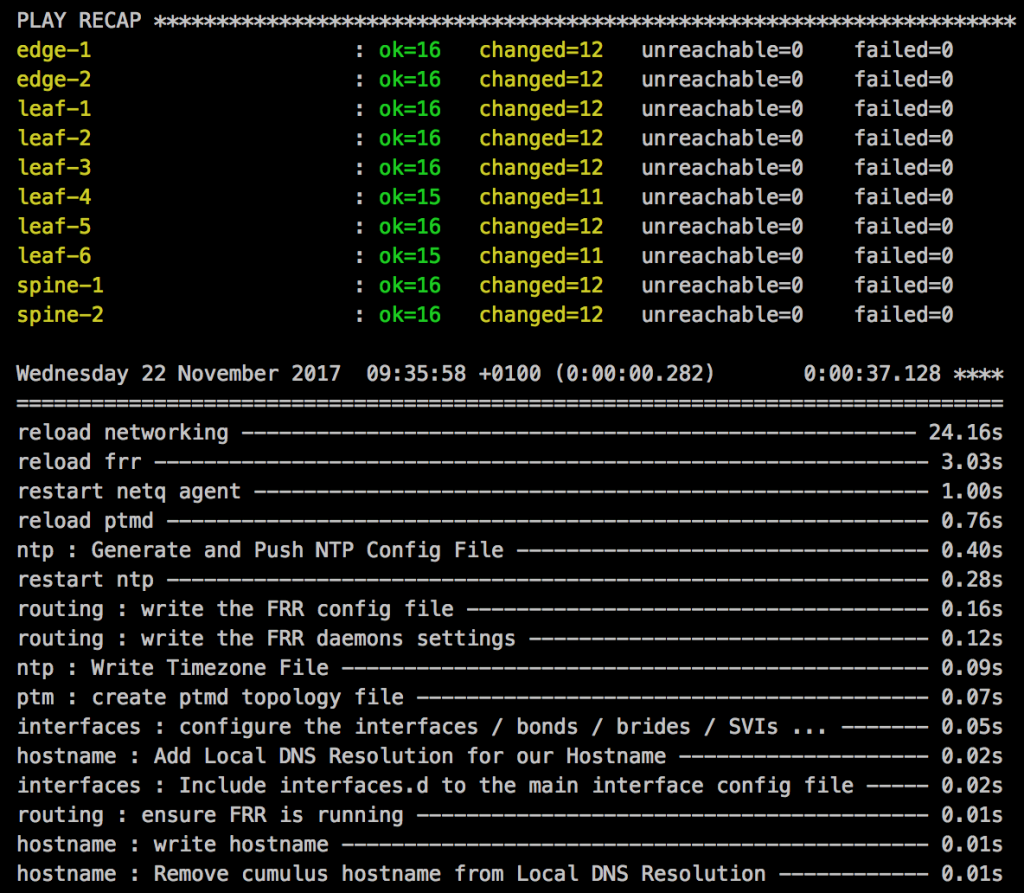
Output if you start the environment:
berndonline@lab:~/cumulus-lab-vagrant$ vagrant up spine-1
Bringing machine 'spine-1' up with 'libvirt' provider...
==> spine-1: Creating image (snapshot of base box volume).
==> spine-1: Creating domain with the following settings...
==> spine-1: -- Name: cumulus-lab-vagrant_spine-1
==> spine-1: -- Domain type: kvm
==> spine-1: -- Cpus: 1
==> spine-1: -- Feature: acpi
==> spine-1: -- Feature: apic
==> spine-1: -- Feature: pae
==> spine-1: -- Memory: 512M
==> spine-1: -- Management MAC:
==> spine-1: -- Loader:
==> spine-1: -- Base box: CumulusCommunity/cumulus-vx
==> spine-1: -- Storage pool: default
==> spine-1: -- Image: /var/lib/libvirt/images/cumulus-lab-vagrant_spine-1.img (4G)
==> spine-1: -- Volume Cache: default
==> spine-1: -- Kernel:
==> spine-1: -- Initrd:
==> spine-1: -- Graphics Type: vnc
==> spine-1: -- Graphics Port: 5900
==> spine-1: -- Graphics IP: 127.0.0.1
==> spine-1: -- Graphics Password: Not defined
==> spine-1: -- Video Type: cirrus
==> spine-1: -- Video VRAM: 9216
==> spine-1: -- Sound Type:
==> spine-1: -- Keymap: en-us
==> spine-1: -- TPM Path:
==> spine-1: -- INPUT: type=mouse, bus=ps2
==> spine-1: Creating shared folders metadata...
==> spine-1: Starting domain.
==> spine-1: Waiting for domain to get an IP address...
==> spine-1: Waiting for SSH to become available...
spine-1:
spine-1: Vagrant insecure key detected. Vagrant will automatically replace
spine-1: this with a newly generated keypair for better security.
spine-1:
spine-1: Inserting generated public key within guest...
spine-1: Removing insecure key from the guest if it's present...
spine-1: Key inserted! Disconnecting and reconnecting using new SSH key...
==> spine-1: Setting hostname...
==> spine-1: Configuring and enabling network interfaces...
....
==> spine-1: #################################
==> spine-1: Running Switch Post Config (config_vagrant_switch.sh)
==> spine-1: #################################
==> spine-1: ###Creating SSH keys for cumulus user ###
==> spine-1: #################################
==> spine-1: Finished
==> spine-1: #################################
==> spine-1: Running provisioner: shell...
spine-1: Running: inline script
==> spine-1: Running provisioner: shell...
spine-1: Running: inline script
==> spine-1: INFO: Adding UDEV Rule: a0:00:00:00:00:21 --> eth0
==> spine-1: Running provisioner: shell...
spine-1: Running: inline script
==> spine-1: INFO: Adding UDEV Rule: 44:38:39:00:00:30 --> swp1
==> spine-1: Running provisioner: shell...
spine-1: Running: inline script
==> spine-1: INFO: Adding UDEV Rule: 44:38:39:00:00:04 --> swp2
==> spine-1: Running provisioner: shell...
spine-1: Running: inline script
==> spine-1: INFO: Adding UDEV Rule: 44:38:39:00:00:26 --> swp3
==> spine-1: Running provisioner: shell...
spine-1: Running: inline script
==> spine-1: INFO: Adding UDEV Rule: 44:38:39:00:00:0a --> swp4
==> spine-1: Running provisioner: shell...
spine-1: Running: inline script
==> spine-1: INFO: Adding UDEV Rule: 44:38:39:00:00:22 --> swp51
==> spine-1: Running provisioner: shell...
spine-1: Running: inline script
==> spine-1: INFO: Adding UDEV Rule: 44:38:39:00:00:0d --> swp52
==> spine-1: Running provisioner: shell...
spine-1: Running: inline script
==> spine-1: INFO: Adding UDEV Rule: 44:38:39:00:00:10 --> swp53
==> spine-1: Running provisioner: shell...
spine-1: Running: inline script
==> spine-1: INFO: Adding UDEV Rule: 44:38:39:00:00:23 --> swp54
==> spine-1: Running provisioner: shell...
spine-1: Running: inline script
==> spine-1: INFO: Adding UDEV Rule: Vagrant interface = eth1
==> spine-1: #### UDEV Rules (/etc/udev/rules.d/70-persistent-net.rules) ####
==> spine-1: ACTION=="add", SUBSYSTEM=="net", ATTR{address}=="a0:00:00:00:00:21", NAME="eth0", SUBSYSTEMS=="pci"
==> spine-1: ACTION=="add", SUBSYSTEM=="net", ATTR{address}=="44:38:39:00:00:30", NAME="swp1", SUBSYSTEMS=="pci"
==> spine-1: ACTION=="add", SUBSYSTEM=="net", ATTR{address}=="44:38:39:00:00:04", NAME="swp2", SUBSYSTEMS=="pci"
==> spine-1: ACTION=="add", SUBSYSTEM=="net", ATTR{address}=="44:38:39:00:00:26", NAME="swp3", SUBSYSTEMS=="pci"
==> spine-1: ACTION=="add", SUBSYSTEM=="net", ATTR{address}=="44:38:39:00:00:0a", NAME="swp4", SUBSYSTEMS=="pci"
==> spine-1: ACTION=="add", SUBSYSTEM=="net", ATTR{address}=="44:38:39:00:00:22", NAME="swp51", SUBSYSTEMS=="pci"
==> spine-1: ACTION=="add", SUBSYSTEM=="net", ATTR{address}=="44:38:39:00:00:0d", NAME="swp52", SUBSYSTEMS=="pci"
==> spine-1: ACTION=="add", SUBSYSTEM=="net", ATTR{address}=="44:38:39:00:00:10", NAME="swp53", SUBSYSTEMS=="pci"
==> spine-1: ACTION=="add", SUBSYSTEM=="net", ATTR{address}=="44:38:39:00:00:23", NAME="swp54", SUBSYSTEMS=="pci"
==> spine-1: ACTION=="add", SUBSYSTEM=="net", ATTR{ifindex}=="2", NAME="eth1", SUBSYSTEMS=="pci"
==> spine-1: Running provisioner: shell...
spine-1: Running: inline script
==> spine-1: ### RUNNING CUMULUS EXTRA CONFIG ###
==> spine-1: INFO: Detected a 3.x Based Release
==> spine-1: ### Disabling default remap on Cumulus VX...
==> spine-1: ### Disabling ZTP service...
==> spine-1: Removed symlink /etc/systemd/system/multi-user.target.wants/ztp.service.
==> spine-1: ### Resetting ZTP to work next boot...
==> spine-1: Created symlink from /etc/systemd/system/multi-user.target.wants/ztp.service to /lib/systemd/system/ztp.service.
==> spine-1: INFO: Detected Cumulus Linux v3.3.2 Release
==> spine-1: ### Fixing ONIE DHCP to avoid Vagrant Interface ###
==> spine-1: Note: Installing from ONIE will undo these changes.
==> spine-1: ### Giving Vagrant User Ability to Run NCLU Commands ###
==> spine-1: ### DONE ###
==> spine-1: ### Rebooting Device to Apply Remap...
At the end you are able to connect to the Cumulus switch:
berndonline@lab:~/cumulus-lab-vagrant$ vagrant ssh spine-1
Welcome to Cumulus VX (TM)
Cumulus VX (TM) is a community supported virtual appliance designed for
experiencing, testing and prototyping Cumulus Networks' latest technology.
For any questions or technical support, visit our community site at:
http://community.cumulusnetworks.com
The registered trademark Linux (R) is used pursuant to a sublicense from LMI,
the exclusive licensee of Linus Torvalds, owner of the mark on a world-wide
basis.
vagrant@cumulus:~$
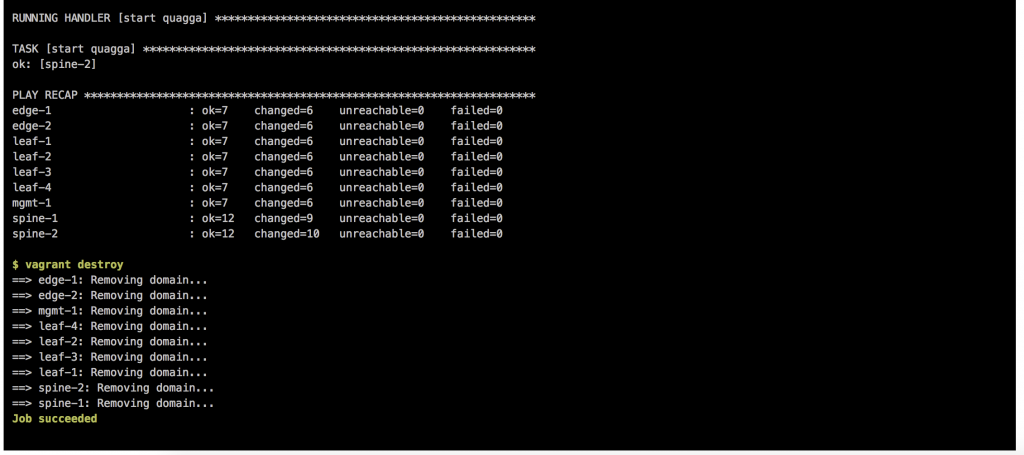
To destroy the Vagrant environment:
berndonline@lab:~/cumulus-lab-vagrant$ vagrant destroy spine-1
==> spine-2: Remove stale volume...
==> spine-2: Domain is not created. Please run `vagrant up` first.
==> spine-1: Removing domain...
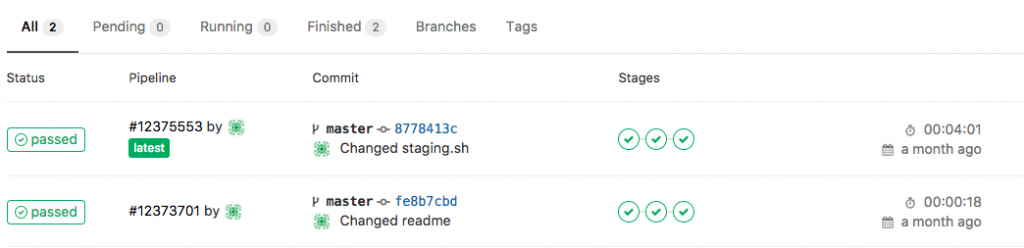
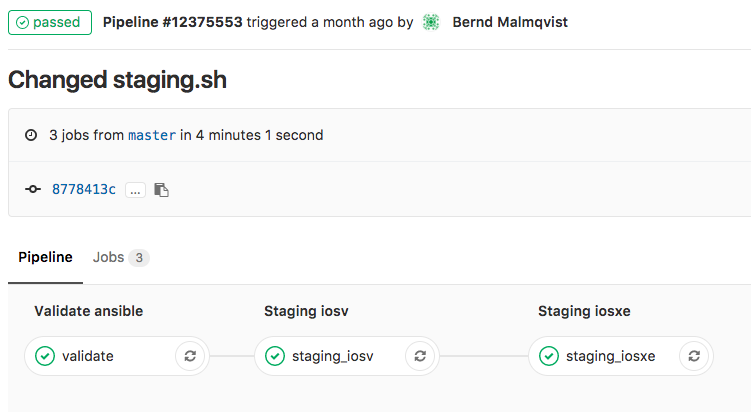
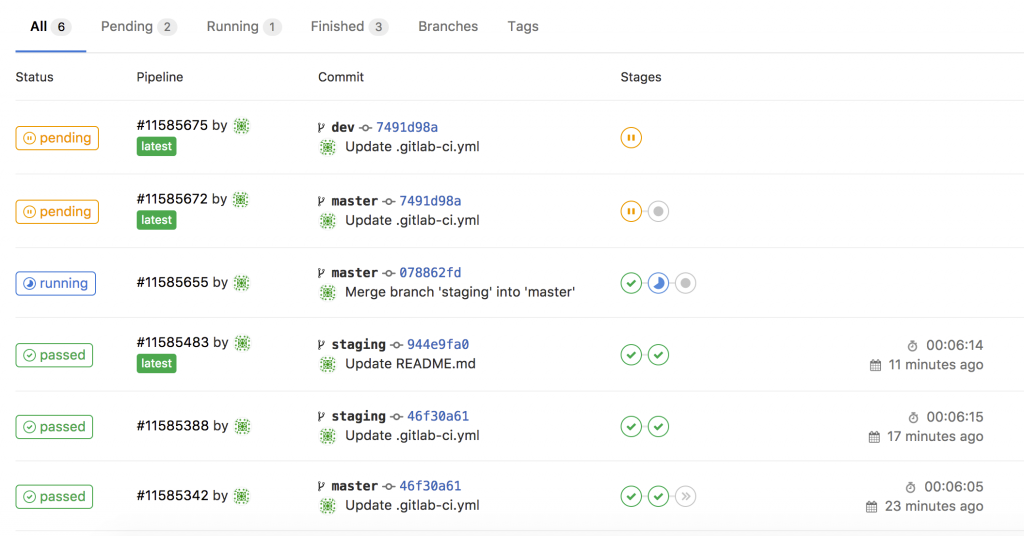
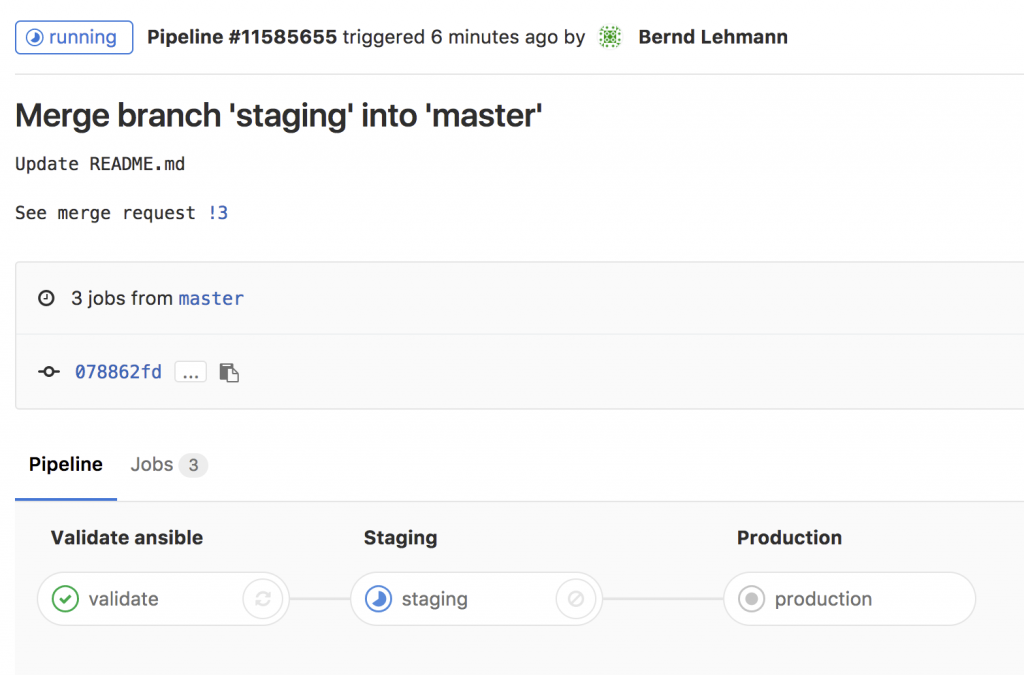
My goal is to adopt some NetDevOps practice and use this in networking = NetOps, currently working on an Continuous Integration and Delivery (CI/CD) pipeline for Cumulus Linux network environments. The Vagrant lab was one of the prerequisites to simulate the changes before deploying this to production but more will follow in my next blog post.
Read my new post about an Ansible Playbook for Cumulus Linux BGP IP-Fabric and Cumulus NetQ Validation.