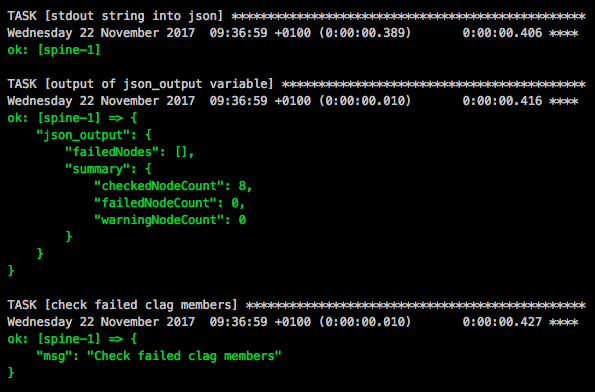
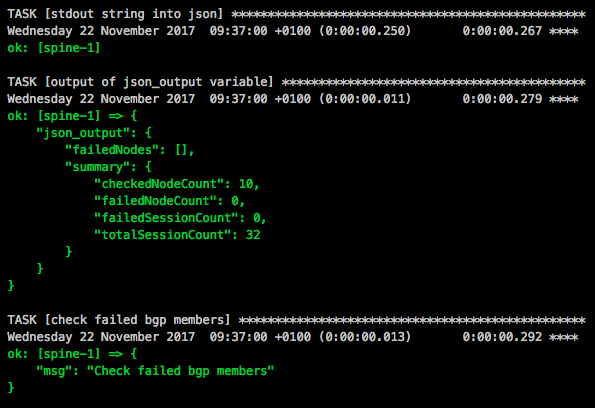
I did some updates on my Cumulus Linux Vagrant topology and added new functions to my post about an Ansible Playbook for the Cumulus Linux BGP IP-Fabric.
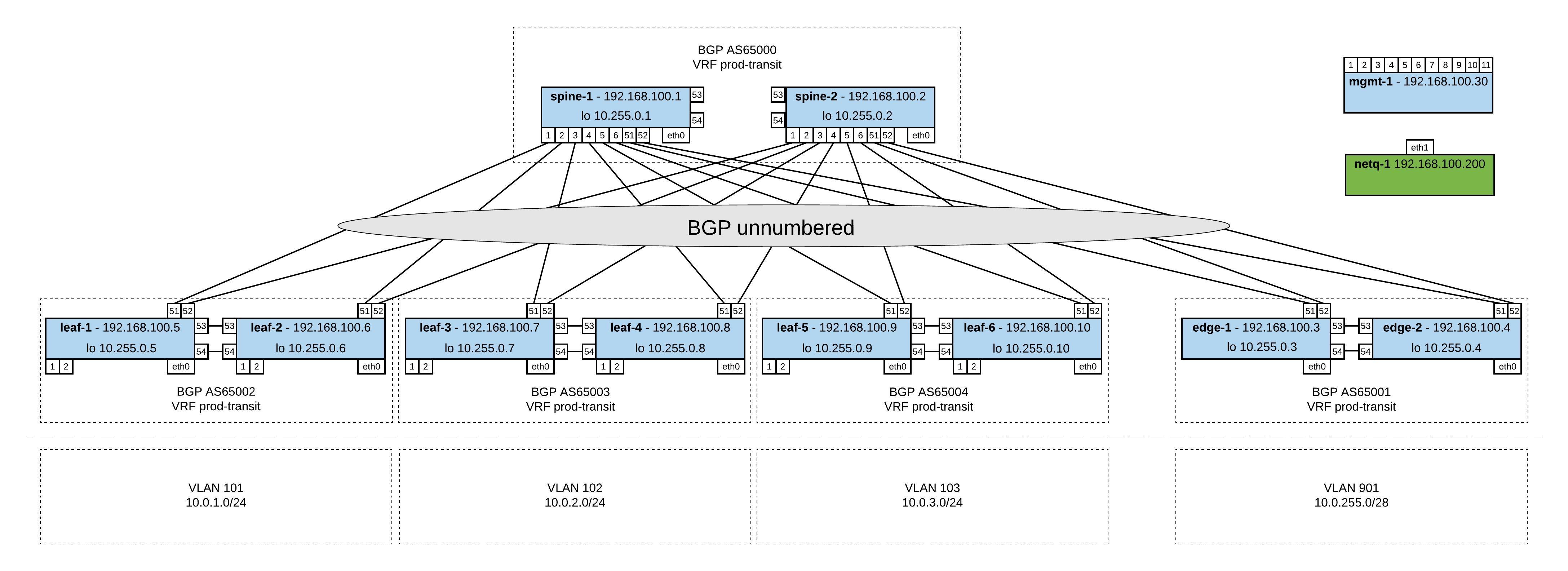
To the Vagrant topology, I added 6x servers and per clag-pair, each server is connected to a VLAN and the second server is connected to a VXLAN.
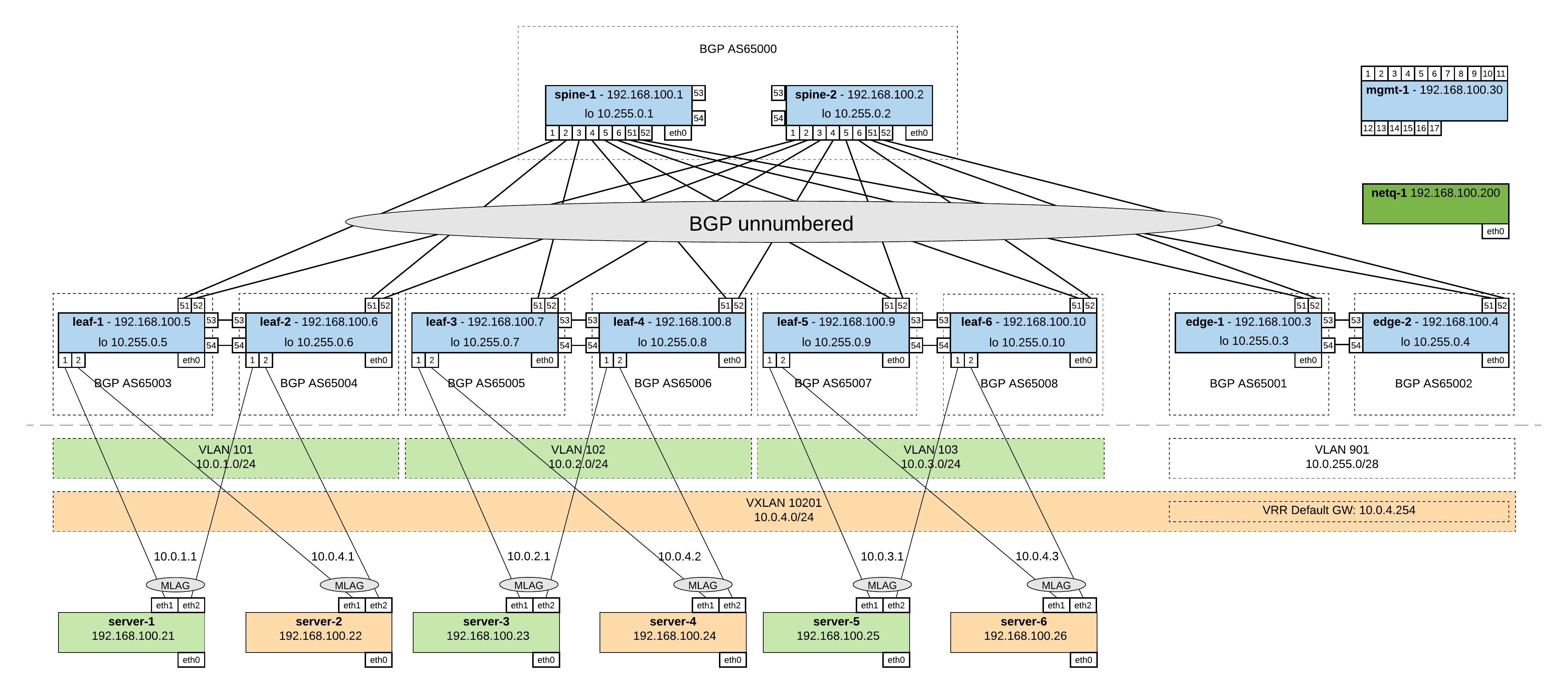
Here are the links to the repositories where you find the Ansible Playbook https://github.com/berndonline/cumulus-lab-provision and the Vagrantfile https://github.com/berndonline/cumulus-lab-vagrant
In the Ansible Playbook, I added BGP EVPN and one VXLAN which spreads over all Leaf and Edge switches. VXLAN routing is happening on the Edge switches into the rest of the virtual data centre network.
Here is an example of the additional variables I added to edge-1 for BGP EVPN and VXLAN:
group_vars/edge.yml:
clagd_vxlan_anycast_ip: 10.255.100.1
The VXLAN anycast IP is needed in BGP for EVPN and the same IP is shared between edge-1 and edge-2. The same is for the other leaf switches, per clag pair they share the same anycast IP address.
host_vars/edge-1.yml:
---
loopback: 10.255.0.3/32
bgp_fabric:
asn: 65001
router_id: 10.255.0.3
neighbor:
- swp51
- swp52
networks:
- 10.0.4.0/24
- 10.255.0.3/32
- 10.255.100.1/32
- 10.0.255.0/28
evpn: true
advertise_vni: true
peerlink:
bond_slaves: swp53 swp54
mtu: 9216
vlan: 4094
address: 169.254.1.1/30
clagd_peer_ip: 169.254.1.2
clagd_backup_ip: 192.168.100.4
clagd_sys_mac: 44:38:39:FF:40:94
clagd_priority: 4096
bridge:
ports: peerlink vxlan10201
vids: 901 201
vlans:
901:
alias: edge-transit-901
vipv4: 10.0.255.14/28
vmac: 00:00:5e:00:09:01
pipv4: 10.0.255.12/28
201:
alias: prod-server-10201
vipv4: 10.0.4.254/24
vmac: 00:00:00:00:02:01
pipv4: 10.0.4.252/24
vlan_id: 201
vlan_raw_device: bridge
vxlans:
10201:
alias: prod-server-10201
vxlan_local_tunnelip: 10.255.0.3
bridge_access: 201
bridge_learning: 'off'
bridge_arp_nd_suppress: 'on'
On the Edge switches, because of VXLAN routing, you find a mapping between VXLAN 10201 to VLAN 201 which has VRR running.
I needed to do some modifications to the interfaces template interfaces_config.j2:
{% if loopback is defined %}
auto lo
iface lo inet loopback
address {{ loopback }}
{% if clagd_vxlan_anycast_ip is defined %}
clagd-vxlan-anycast-ip {{ clagd_vxlan_anycast_ip }}
{% endif %}
{% endif %}
...
{% if bridge is defined %}
{% for vxlan_id, value in vxlans.items() %}
auto vxlan{{ vxlan_id }}
iface vxlan{{ vxlan_id }}
alias {{ value.alias }}
vxlan-id {{ vxlan_id }}
vxlan-local-tunnelip {{ value.vxlan_local_tunnelip }}
bridge-access {{ value.bridge_access }}
bridge-learning {{ value.bridge_learning }}
bridge-arp-nd-suppress {{ value.bridge_arp_nd_suppress }}
mstpctl-bpduguard yes
mstpctl-portbpdufilter yes
{% endfor %}
{% endif %}
There were also some modifications needed to the FRR template frr.j2 to add EVPN to the BGP configuration:
...
{% if bgp_fabric.evpn is defined %}
address-family ipv6 unicast
neighbor fabric activate
exit-address-family
!
address-family l2vpn evpn
neighbor fabric activate
{% if bgp_fabric.advertise_vni is defined %}
advertise-all-vni
{% endif %}
exit-address-family
{% endif %}
{% endif %}
...
For more detailed information about EVPN and VXLAN routing on Cumulus Linux, I recommend reading the documentation Ethernet Virtual Private Network – EVPN and VXLAN Routing.
Have fun testing the new features in my Ansible Playbook and please share your feedback.