It has been some time since my last post but I want to continue my OpenShift Hive article series about Getting started with OpenShift Hive and how to Deploy OpenShift/OKD 4.x clusters using Hive. In this blog post I want to explain how you can use Hive to synchronise cluster configuration using SyncSets. There are two different types of SyncSets, the SyncSet (namespaced custom resource), which you assign to a specific cluster name in the Cluster Deployment Reference, and a SelectorSyncSet (cluster-wide custom resource) using the Cluster Deployment Selector, which uses a label selector to apply configuration to a set of clusters matching the label across cluster namespaces.
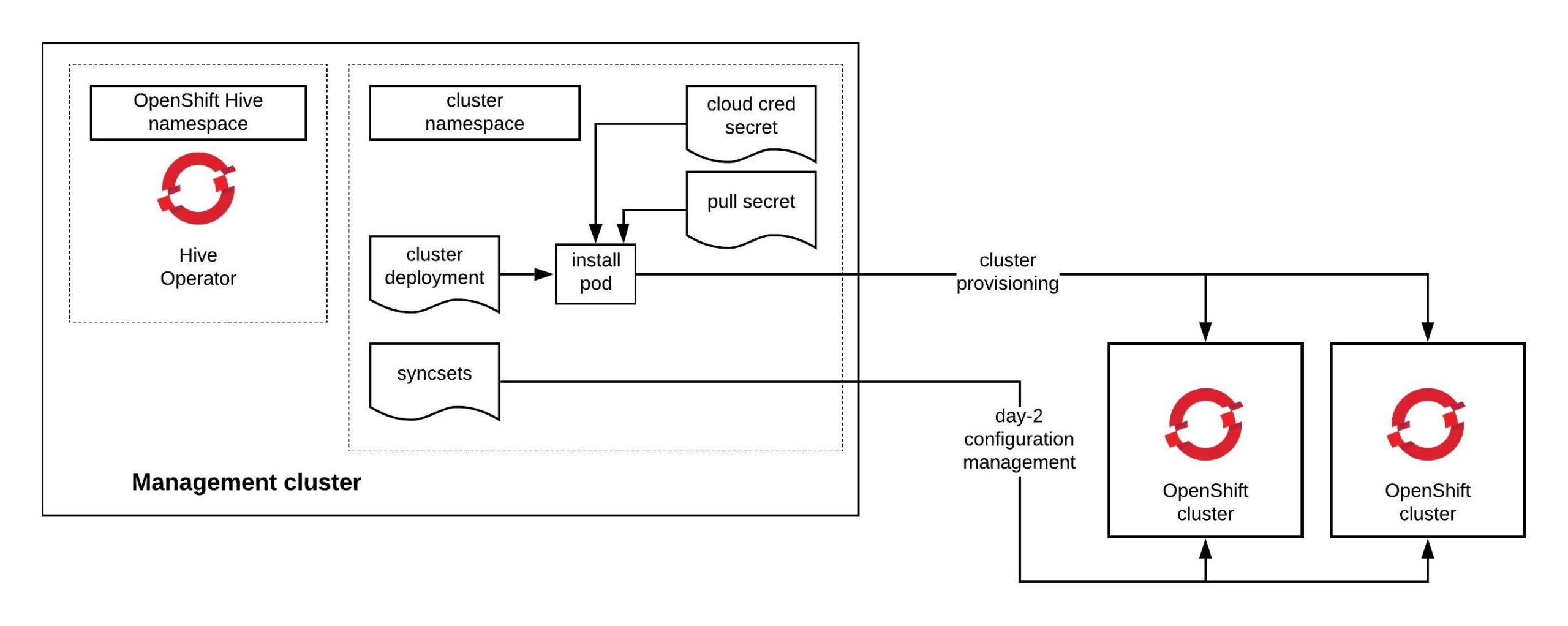
Let’s look at the first example of a SyncSet (namespaced resource), which you can see in the example below. In the clusterDeploymentRefs you need to match a cluster name which is created in the same namespace where you create the SyncSet. In SyncSet there are sections where you can create resources or apply patches to a cluster. The last section is secretReference which you use to apply secrets to a cluster without having them in clear text written in the SyncSet:
apiVersion: hive.openshift.io/v1
kind: SyncSet
metadata:
name: example-syncset
namespace: okd
spec:
clusterDeploymentRefs:
- name: okd
resources:
- apiVersion: v1
kind: Namespace
metadata:
name: myproject
patches:
- kind: Config
apiVersion: imageregistry.operator.openshift.io/v1
name: cluster
applyMode: AlwaysApply
patch: |-
{ "spec": { "defaultRoute": true }}
patchType: merge
secretReferences:
- source:
name: mysecret
namespace: okd
target:
name: mysecret
namespace: myproject
The second SyncSet example for an SelectorSyncSet (cluster-wide resource) is very similar to the previous example but more flexible because you can use a label selector clusterDeploymentSelector and the configuration can be applied to multiple clusters matching the label across cluster namespaces. Great use-case for common or environment configuration which is the same for all OpenShift clusters:
---
apiVersion: hive.openshift.io/v1
kind: SelectorSyncSet
metadata:
name: mygroup
spec:
resources:
- apiVersion: v1
kind: Namespace
metadata:
name: myproject
resourceApplyMode: Sync
clusterDeploymentSelector:
matchLabels:
cluster-group: okd
The problem with SyncSets is that they can get pretty large and it is complicated to write them by yourself depending on the size of configuration. My colleague Matt wrote a syncset generator which solves the problem and automatically generates a SelectorSyncSet, please checkout his github repository:
$ wget -O syncset-gen https://github.com/matt-simons/syncset-gen/releases/download/v0.5/syncset-gen_linux_amd64 && chmod +x ./syncset-gen $ sudo mv ./syncset-gen /usr/bin/ $ syncset-gen view -h Parses a manifest directory and prints a SyncSet/SelectorSyncSet representation of the objects it contains. Usage: ss view [flags] Flags: -c, --cluster-name string The cluster name used to match the SyncSet to a Cluster -h, --help help for view -p, --patches string The directory of patch manifest files to use -r, --resources string The directory of resource manifest files to use -s, --selector string The selector key/value pair used to match the SelectorSyncSet to Cluster(s)
Next we need a repository to store the configuration for the OpenShift/OKD clusters. Below you can see a very simple example. The ./config folder contains common configuration which is using a SelectorSyncSet with a clusterDeploymentSelector:
$ tree
.
└── config
├── patch
│ └── cluster-version.yaml
└── resource
└── namespace.yaml
To generate a SelectorSyncSet from the ./config folder, run the syncset-gen and the following command options:
$ syncset-gen view okd-cluster-group-selectorsyncset --selector cluster-group/okd -p ./config/patch/ -r ./config/resource/
{
"kind": "SelectorSyncSet",
"apiVersion": "hive.openshift.io/v1",
"metadata": {
"name": "okd-cluster-group-selectorsyncset",
"creationTimestamp": null,
"labels": {
"generated": "true"
}
},
"spec": {
"resources": [
{
"apiVersion": "v1",
"kind": "Namespace",
"metadata": {
"name": "myproject"
}
}
],
"resourceApplyMode": "Sync",
"patches": [
{
"apiVersion": "config.openshift.io/v1",
"kind": "ClusterVersion",
"name": "version",
"patch": "{\"spec\": {\"channel\": \"stable-4.3\",\"desiredUpdate\": {\"version\": \"4.3.0\", \"image\": \"quay.io/openshift-release-dev/ocp-release@sha256:3a516480dfd68e0f87f702b4d7bdd6f6a0acfdac5cd2e9767b838ceede34d70d\"}}}",
"patchType": "merge"
},
{
"apiVersion": "rbac.authorization.k8s.io/v1",
"kind": "ClusterRoleBinding",
"name": "self-provisioners",
"patch": "{\"subjects\": null}",
"patchType": "merge"
}
],
"clusterDeploymentSelector": {
"matchExpressions": [
{
"key": "cluster-group/okd",
"operator": "Exists"
}
]
}
},
"status": {}
}
To debug SyncSets use the below command in the cluster deployment namespace which can give you a status of whether the configuration has successfully applied or if it has failed to apply:
$ oc get syncsetinstance -n <namespace> $ oc get syncsetinstances <synsetinstance name> -o yaml
I hope this was useful to get you started using OpenShift Hive and SyncSets to apply configuration to OpenShift/OKD clusters. More information about SyncSets can be found in the OpenShift Hive repository.