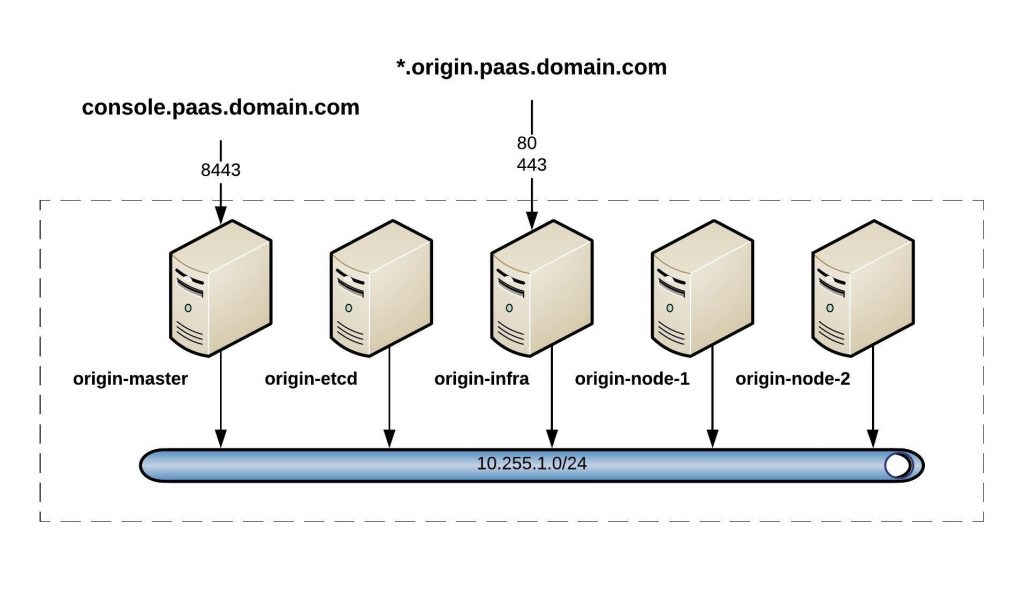
Before you continue to deploy an OpenShift or OKD cluster please check out my other posts about OpenShift Hive – API driven OpenShift cluster provisioning and management operator and Getting started with OpenShift Hive because you need a running OpenShift Hive operator.
To install the OKD (OpenShift Origin Community Distribution) version we need a few things beforehand: a cluster namespace, AWS credentials, SSH keys, image pull secret, install-config, cluster image version and cluster deployment.
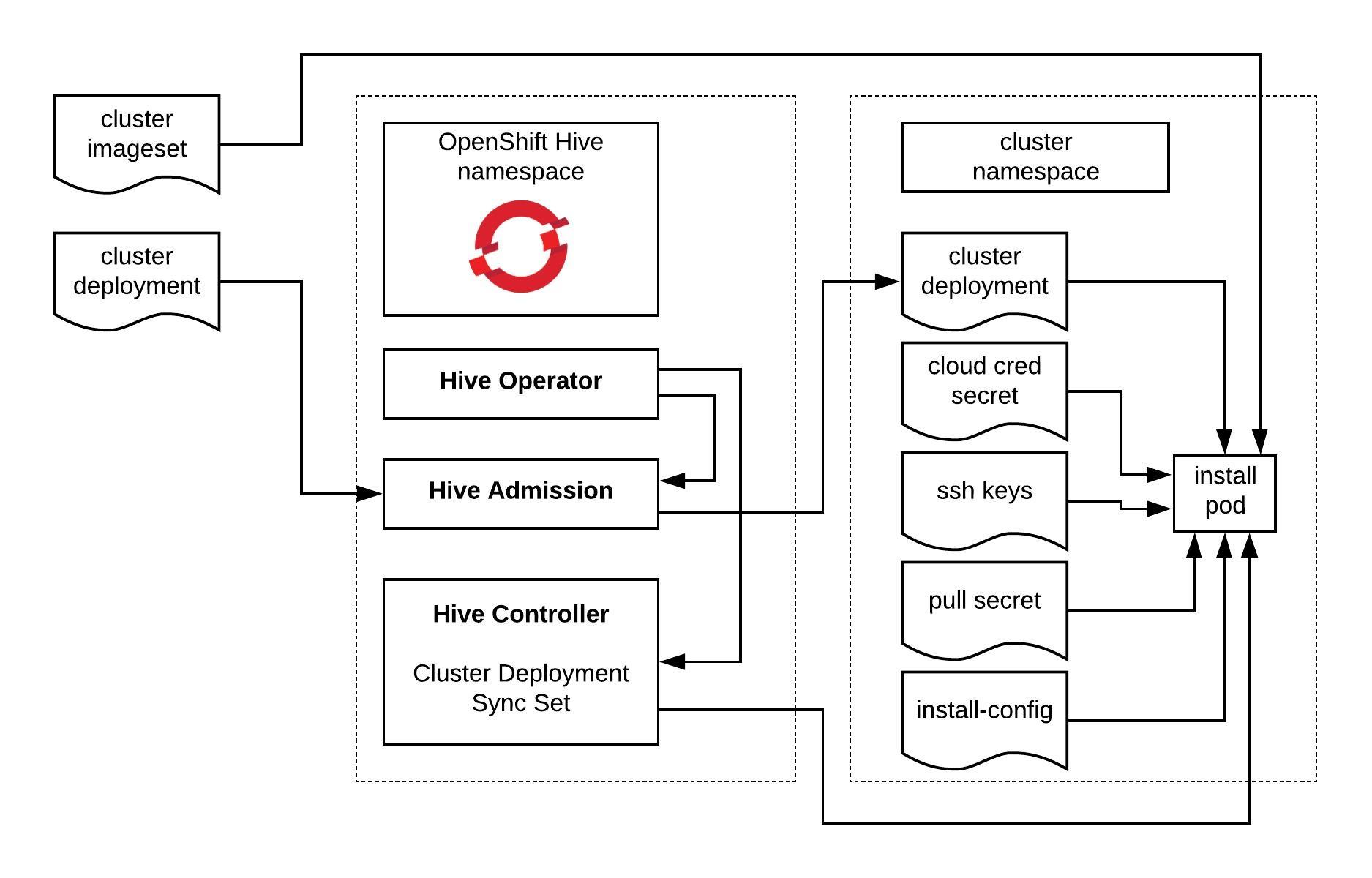
Let’s start to create the cluster namespace:
cat <<EOF | kubectl apply -f - --- apiVersion: v1 kind: Namespace metadata: name: okd
Create a secret with your ssh key:
$ kubectl create secret generic ssh-key -n okd --from-file=ssh-privatekey=/home/ubuntu/.ssh/id_rsa --from-file=ssh-publickey=/home/ubuntu/.ssh/id_rsa.pub
Create the AWS credential secret:
$ kubectl create secret generic aws-creds -n okd --from-literal=aws_secret_access_key=$AWS_SECRET_ACCESS_KEY --from-literal=aws_access_key_id=$AWS_ACCESS_KEY_ID
Create an image pull secret, this is not important for installing a OKD 4.x cluster but needs to be present otherwise Hive will not start the cluster deployment. If you have an RedHat Enterprise subscription for OpenShift then you need to add here your RedHat image pull secret:
$ kubectl create secret generic pull-secret -n okd --from-file=.dockerconfigjson=/home/ubuntu/.docker/config.json --type=kubernetes.io/dockerconfigjson
Create a install-config.yaml for the cluster deployment and modify to your needs:
---
apiVersion: v1
baseDomain: kube.domain.com
compute:
- name: worker
platform:
aws:
rootVolume:
iops: 100
size: 22
type: gp2
type: m4.xlarge
replicas: 3
controlPlane:
name: master
platform:
aws:
rootVolume:
iops: 100
size: 22
type: gp2
type: m4.xlarge
replicas: 3
metadata:
creationTimestamp: null
name: okd
networking:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
machineCIDR: 10.0.0.0/16
networkType: OpenShiftSDN
serviceNetwork:
- 172.30.0.0/16
platform:
aws:
region: eu-west-1
pullSecret: ""
sshKey: ""
Create the install-config secret for the cluster deployment:
$ kubectl create secret generic install-config -n okd --from-file=install-config.yaml=./install-config.yaml
Create the ClusterImageSet for OKD. In my example I am using the latest OKD 4.4.0 release. More information about the available OKD release versions you find here: https://origin-release.svc.ci.openshift.org/
cat <<EOF | kubectl apply -f - --- apiVersion: hive.openshift.io/v1 kind: ClusterImageSet metadata: name: okd-4-4-0-imageset spec: releaseImage: registry.svc.ci.openshift.org/origin/release:4.4.0-0.okd-2020-02-18-212654 EOF
Below is an example of a RedHat Enterprise OpenShift 4 ClusterImageSet:
--- apiVersion: hive.openshift.io/v1 kind: ClusterImageSet metadata: name: openshift-4-3-0-imageset spec: releaseImage: quay.io/openshift-release-dev/ocp-release:4.3.0-x86_64
For Hive to start with the cluster deployment, we need to modify the manifest below and add the references to the previous created secrets, install-config and cluster imageset version:
cat <<EOF | kubectl apply -f -
---
apiVersion: hive.openshift.io/v1
kind: ClusterDeployment
metadata:
creationTimestamp: null
name: okd
namespace: okd
spec:
baseDomain: kube.domain.com
clusterName: okd
controlPlaneConfig:
servingCertificates: {}
installed: false
platform:
aws:
credentialsSecretRef:
name: aws-creds
region: eu-west-1
provisioning:
imageSetRef:
name: okd-4-4-0-imageset
installConfigSecretRef:
name: install-config
pullSecretRef:
name: pull-secret
sshKey:
name: ssh-key
status:
clusterVersionStatus:
availableUpdates: null
desired:
force: false
image: ""
version: ""
observedGeneration: 0
versionHash: ""
EOF
Once you submitted the ClusterDeployment manifest, the Hive operator will start to deploy the cluster straightaway:
$ kubectl get clusterdeployments.hive.openshift.io -n okd NAME CLUSTERNAME CLUSTERTYPE BASEDOMAIN INSTALLED INFRAID AGE okd okd kube.domain.com false okd-jcdkd 107s
Hive will create the provision (install) pod for the cluster deployment and inject the installer configuration:
$ kubectl get pods -n okd NAME READY STATUS RESTARTS AGE okd-0-tbm9t-provision-c5hpf 1/3 Running 0 57s
You can view the logs to check the progress of the cluster deployment. You will see the terraform output for creating the infrastructure resources and feedback from the installer about the installation progress. At the end you will see when the installation completed successfully:
$ kubectl logs okd-0-tbm9t-provision-c5hpf -n okd -c hive -f ... time="2020-02-23T13:31:41Z" level=debug msg="module.dns.aws_route53_zone.int: Creating..." time="2020-02-23T13:31:42Z" level=debug msg="aws_ami_copy.main: Still creating... [3m40s elapsed]" time="2020-02-23T13:31:51Z" level=debug msg="module.dns.aws_route53_zone.int: Still creating... [10s elapsed]" time="2020-02-23T13:31:52Z" level=debug msg="aws_ami_copy.main: Still creating... [3m50s elapsed]" time="2020-02-23T13:32:01Z" level=debug msg="module.dns.aws_route53_zone.int: Still creating... [20s elapsed]" time="2020-02-23T13:32:02Z" level=debug msg="aws_ami_copy.main: Still creating... [4m0s elapsed]" time="2020-02-23T13:32:11Z" level=debug msg="module.dns.aws_route53_zone.int: Still creating... [30s elapsed]" time="2020-02-23T13:32:12Z" level=debug msg="aws_ami_copy.main: Still creating... [4m10s elapsed]" time="2020-02-23T13:32:21Z" level=debug msg="module.dns.aws_route53_zone.int: Still creating... [40s elapsed]" time="2020-02-23T13:32:22Z" level=debug msg="aws_ami_copy.main: Still creating... [4m20s elapsed]" time="2020-02-23T13:32:31Z" level=debug msg="module.dns.aws_route53_zone.int: Still creating... [50s elapsed]" time="2020-02-23T13:32:32Z" level=debug msg="aws_ami_copy.main: Still creating... [4m30s elapsed]" time="2020-02-23T13:32:41Z" level=debug msg="module.dns.aws_route53_zone.int: Still creating... [1m0s elapsed]" time="2020-02-23T13:32:41Z" level=debug msg="module.dns.aws_route53_zone.int: Creation complete after 1m0s [id=Z10411051RAEUMMAUH39E]" time="2020-02-23T13:32:41Z" level=debug msg="module.dns.aws_route53_record.etcd_a_nodes[0]: Creating..." time="2020-02-23T13:32:41Z" level=debug msg="module.dns.aws_route53_record.api_internal: Creating..." time="2020-02-23T13:32:41Z" level=debug msg="module.dns.aws_route53_record.api_external_internal_zone: Creating..." time="2020-02-23T13:32:41Z" level=debug msg="module.dns.aws_route53_record.etcd_a_nodes[2]: Creating..." time="2020-02-23T13:32:41Z" level=debug msg="module.dns.aws_route53_record.etcd_a_nodes[1]: Creating..." time="2020-02-23T13:32:42Z" level=debug msg="aws_ami_copy.main: Still creating... [4m40s elapsed]" time="2020-02-23T13:32:51Z" level=debug msg="module.dns.aws_route53_record.etcd_a_nodes[0]: Still creating... [10s elapsed]" time="2020-02-23T13:32:51Z" level=debug msg="module.dns.aws_route53_record.api_internal: Still creating... [10s elapsed]" time="2020-02-23T13:32:51Z" level=debug msg="module.dns.aws_route53_record.api_external_internal_zone: Still creating... [10s elapsed]" time="2020-02-23T13:32:51Z" level=debug msg="module.dns.aws_route53_record.etcd_a_nodes[2]: Still creating... [10s elapsed]" time="2020-02-23T13:32:51Z" level=debug msg="module.dns.aws_route53_record.etcd_a_nodes[1]: Still creating... [10s elapsed]" time="2020-02-23T13:32:52Z" level=debug msg="aws_ami_copy.main: Still creating... [4m50s elapsed]" ... time="2020-02-23T13:34:43Z" level=debug msg="Apply complete! Resources: 123 added, 0 changed, 0 destroyed." time="2020-02-23T13:34:43Z" level=debug msg="OpenShift Installer unreleased-master-2446-gc108297de972e1a6a5fb502a7668079d16e501f9-dirty" time="2020-02-23T13:34:43Z" level=debug msg="Built from commit c108297de972e1a6a5fb502a7668079d16e501f9" time="2020-02-23T13:34:43Z" level=info msg="Waiting up to 20m0s for the Kubernetes API at https://api.okd.kube.domain.com:6443..." time="2020-02-23T13:35:13Z" level=debug msg="Still waiting for the Kubernetes API: Get https://api.okd.kube.domain.com:6443/version?timeout=32s: dial tcp 52.17.210.160:6443: connect: connection refused" time="2020-02-23T13:35:50Z" level=debug msg="Still waiting for the Kubernetes API: Get https://api.okd.kube.domain.com:6443/version?timeout=32s: dial tcp 52.211.227.216:6443: connect: connection refused" time="2020-02-23T13:36:20Z" level=debug msg="Still waiting for the Kubernetes API: Get https://api.okd.kube.domain.com:6443/version?timeout=32s: dial tcp 52.17.210.160:6443: connect: connection refused" time="2020-02-23T13:36:51Z" level=debug msg="Still waiting for the Kubernetes API: Get https://api.okd.kube.domain.com:6443/version?timeout=32s: dial tcp 52.211.227.216:6443: connect: connection refused" time="2020-02-23T13:37:58Z" level=debug msg="Still waiting for the Kubernetes API: Get https://api.okd.kube.domain.com:6443/version?timeout=32s: dial tcp 52.211.227.216:6443: connect: connection refused" time="2020-02-23T13:38:00Z" level=debug msg="Still waiting for the Kubernetes API: the server could not find the requested resource" time="2020-02-23T13:38:30Z" level=debug msg="Still waiting for the Kubernetes API: the server could not find the requested resource" time="2020-02-23T13:38:58Z" level=debug msg="Still waiting for the Kubernetes API: Get https://api.okd.kube.domain.com:6443/version?timeout=32s: dial tcp 52.211.227.216:6443: connect: connection refused" time="2020-02-23T13:39:28Z" level=debug msg="Still waiting for the Kubernetes API: Get https://api.okd.kube.domain.com:6443/version?timeout=32s: dial tcp 63.35.50.149:6443: connect: connection refused" time="2020-02-23T13:39:36Z" level=info msg="API v1.17.1 up" time="2020-02-23T13:39:36Z" level=info msg="Waiting up to 40m0s for bootstrapping to complete..." ... time="2020-02-23T13:55:14Z" level=debug msg="Still waiting for the cluster to initialize: Working towards 4.4.0-0.okd-2020-02-18-212654: 97% complete" time="2020-02-23T13:55:24Z" level=debug msg="Still waiting for the cluster to initialize: Working towards 4.4.0-0.okd-2020-02-18-212654: 99% complete" time="2020-02-23T13:57:39Z" level=debug msg="Still waiting for the cluster to initialize: Working towards 4.4.0-0.okd-2020-02-18-212654: 99% complete, waiting on authentication, console, monitoring" time="2020-02-23T13:57:39Z" level=debug msg="Still waiting for the cluster to initialize: Working towards 4.4.0-0.okd-2020-02-18-212654: 99% complete, waiting on authentication, console, monitoring" time="2020-02-23T13:58:54Z" level=debug msg="Still waiting for the cluster to initialize: Working towards 4.4.0-0.okd-2020-02-18-212654: 99% complete" time="2020-02-23T14:01:40Z" level=debug msg="Still waiting for the cluster to initialize: Working towards 4.4.0-0.okd-2020-02-18-212654: 100% complete, waiting on authentication" time="2020-02-23T14:03:24Z" level=debug msg="Cluster is initialized" time="2020-02-23T14:03:24Z" level=info msg="Waiting up to 10m0s for the openshift-console route to be created..." time="2020-02-23T14:03:24Z" level=debug msg="Route found in openshift-console namespace: console" time="2020-02-23T14:03:24Z" level=debug msg="Route found in openshift-console namespace: downloads" time="2020-02-23T14:03:24Z" level=debug msg="OpenShift console route is created" time="2020-02-23T14:03:24Z" level=info msg="Install complete!" time="2020-02-23T14:03:24Z" level=info msg="To access the cluster as the system:admin user when using 'oc', run 'export KUBECONFIG=/output/auth/kubeconfig'" time="2020-02-23T14:03:24Z" level=info msg="Access the OpenShift web-console here: https://console-openshift-console.apps.okd.kube.domain.com" REDACTED LINE OF OUTPUT time="2020-02-23T14:03:25Z" level=info msg="command completed successfully" installID=jcdkd time="2020-02-23T14:03:25Z" level=info msg="saving installer output" installID=jcdkd time="2020-02-23T14:03:25Z" level=debug msg="installer console log: level=info msg=\"Credentials loaded from default AWS environment variables\"\nlevel=info msg=\"Consuming Install Config from target directory\"\nlevel=warning msg=\"Found override for release image. Please be warned, this is not advised\"\nlevel=info msg=\"Consuming Master Machines from target directory\"\nlevel=info msg=\"Consuming Common Manifests from target directory\"\nlevel=info msg=\"Consuming OpenShift Install from target directory\"\nlevel=info msg=\"Consuming Worker Machines from target directory\"\nlevel=info msg=\"Consuming Openshift Manifests from target directory\"\nlevel=info msg=\"Consuming Master Ignition Config from target directory\"\nlevel=info msg=\"Consuming Worker Ignition Config from target directory\"\nlevel=info msg=\"Consuming Bootstrap Ignition Config from target directory\"\nlevel=info msg=\"Creating infrastructure resources...\"\nlevel=info msg=\"Waiting up to 20m0s for the Kubernetes API at https://api.okd.kube.domain.com:6443...\"\nlevel=info msg=\"API v1.17.1 up\"\nlevel=info msg=\"Waiting up to 40m0s for bootstrapping to complete...\"\nlevel=info msg=\"Destroying the bootstrap resources...\"\nlevel=error\nlevel=error msg=\"Warning: Resource targeting is in effect\"\nlevel=error\nlevel=error msg=\"You are creating a plan with the -target option, which means that the result\"\nlevel=error msg=\"of this plan may not represent all of the changes requested by the current\"\nlevel=error msg=configuration.\nlevel=error msg=\"\\t\\t\"\nlevel=error msg=\"The -target option is not for routine use, and is provided only for\"\nlevel=error msg=\"exceptional situations such as recovering from errors or mistakes, or when\"\nlevel=error msg=\"Terraform specifically suggests to use it as part of an error message.\"\nlevel=error\nlevel=error\nlevel=error msg=\"Warning: Applied changes may be incomplete\"\nlevel=error\nlevel=error msg=\"The plan was created with the -target option in effect, so some changes\"\nlevel=error msg=\"requested in the configuration may have been ignored and the output values may\"\nlevel=error msg=\"not be fully updated. Run the following command to verify that no other\"\nlevel=error msg=\"changes are pending:\"\nlevel=error msg=\" terraform plan\"\nlevel=error msg=\"\\t\"\nlevel=error msg=\"Note that the -target option is not suitable for routine use, and is provided\"\nlevel=error msg=\"only for exceptional situations such as recovering from errors or mistakes, or\"\nlevel=error msg=\"when Terraform specifically suggests to use it as part of an error message.\"\nlevel=error\nlevel=info msg=\"Waiting up to 30m0s for the cluster at https://api.okd.kube.domain.com:6443 to initialize...\"\nlevel=info msg=\"Waiting up to 10m0s for the openshift-console route to be created...\"\nlevel=info msg=\"Install complete!\"\nlevel=info msg=\"To access the cluster as the system:admin user when using 'oc', run 'export KUBECONFIG=/output/auth/kubeconfig'\"\nlevel=info msg=\"Access the OpenShift web-console here: https://console-openshift-console.apps.okd.kube.domain.com\"\nREDACTED LINE OF OUTPUT\n" installID=vxghr9br time="2020-02-23T14:03:25Z" level=info msg="install completed successfully" installID=jcdkd
After the installation of the cluster deployment has finished, the Installed value is set to True:
$ kubectl get clusterdeployments.hive.openshift.io -n okd NAME CLUSTERNAME CLUSTERTYPE BASEDOMAIN INSTALLED INFRAID AGE okd okd kube.domain.com true okd-jcdkd 54m
At this point you can start using the platform by getting the login credentials from the cluster credential secret Hive created during the installation:
$ kubectl get secrets -n okd okd-0-tbm9t-admin-password -o jsonpath='{.data.username}' | base64 -d
kubeadmin
$ kubectl get secrets -n okd okd-0-tbm9t-admin-password -o jsonpath='{.data.password}' | base64 -d
2T38d-aETpX-dj2YU-UBN4a
Log in via the command-line or the web console:
To delete the cluster simply delete the ClusterDeployment resources which initiates a cluster deprovision and will delete all related AWS resources. If the deprovision gets stuck, manually delete the uninstall finalizer allowing the cluster deployment to be deleted, but note that this may leave artifacts in your AWS account:
$ kubectl delete clusterdeployments.hive.openshift.io okd -n okd --wait=false clusterdeployment.hive.openshift.io "okd" deleted
Please visit the OpenShift Hive documentation for more information about using Hive.
In the next article I will explain how you can use OpenShift Hive to create, update, delete, patch cluster resources using SyncSets.