I have been using Kubernetes in Docker (KinD) for over a year and it’s ideal when you require an ephemeral Kubernetes cluster for local development or testing. My focus with the bootstrap script was to create a Kubernetes cluster where I can easily customise the configuration, choose the required CNI plugin, the Ingress controller or enable Service Mesh if needed, which is especially important in continuous integration pipelines. I will show you two simple examples below of how I use KinD for testing.
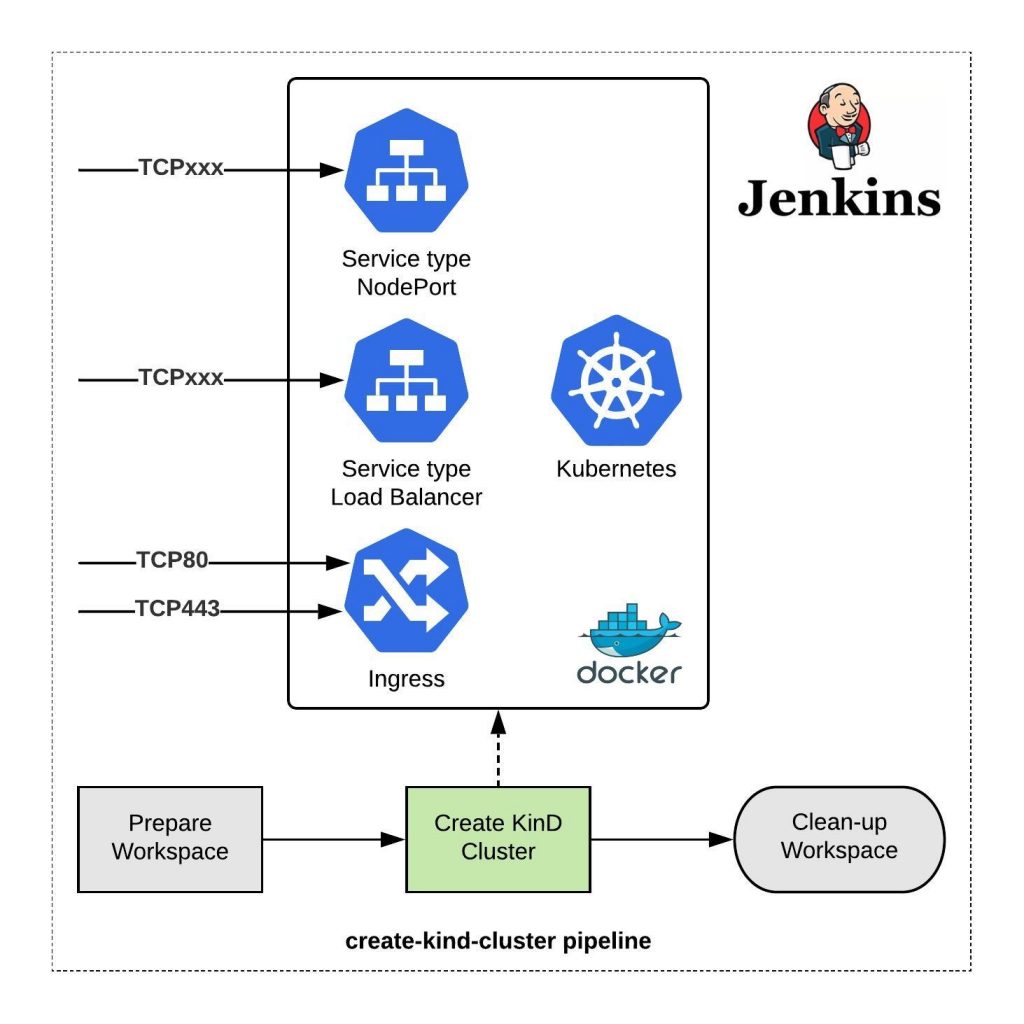
I created the ./kind.sh shell script which does what I need to create a cluster in a couple of minutes and apply the configuration.
-
- Customise cluster configuration like Kubernetes version, the number of worker nodes, change the service- and pod IP address subnet and a couple of other cluster level configuration.
- You can choose from different CNI plugins like KinD-CNI (default), Calico and Cilium, or optionally enable the Multus-CNI on top of the CNI plugin.
- Install the popular known Nginx or Contour Kubernetes ingress controllers. Contour is interesting because it is an Envoy based Ingress controller and can be used for the Kubernetes Gateway API.
- Enable Istio Service Mesh which is also available as a Gateway API option or install MetalLB, a Kubernetes service type load balancer plugin.
- Install Operator Lifecycle Manager (OLM) to install Kubernetes community operators from OperatorHub.io.
$ ./kind.sh --help
usage: kind.sh [--name ]
[--num-workers ]
[--config-file ]
[--kubernetes-version ]
[--cluster-apiaddress ]
[--cluster-apiport ]
[--cluster-loglevel ]
[--cluster-podsubnet ]
[--cluster-svcsubnet ]
[--disable-default-cni]
[--install-calico-cni]
[--install-cilium-cni]
[--install-multus-cni]
[--install-istio]
[--install-metallb]
[--install-nginx-ingress]
[--install-contour-ingress]
[--install-istio-gateway-api]
[--install-contour-gateway-api]
[--install-olm]
[--help]
--name Name of the KIND cluster
DEFAULT: kind
--num-workers Number of worker nodes.
DEFAULT: 0 worker nodes.
--config-file Name of the KIND J2 configuration file.
DEFAULT: ./kind.yaml.j2
--kubernetes-version Flag to specify the Kubernetes version.
DEFAULT: Kubernetes v1.21.1
--cluster-apiaddress Kubernetes API IP address for kind (master).
DEFAULT: 0.0.0.0.
--cluster-apiport Kubernetes API port for kind (master).
DEFAULT: 6443.
--cluster-loglevel Log level for kind (master).
DEFAULT: 4.
--cluster-podsubnet Pod subnet IP address range.
DEFAULT: 10.128.0.0/14.
--cluster-svcsubnet Service subnet IP address range.
DEFAULT: 172.30.0.0/16.
--disable-default-cni Flag to disable Kind default CNI - required to install custom cni plugin.
DEFAULT: Default CNI used.
--install-calico-cni Flag to install Calico CNI Components.
DEFAULT: Don't install calico cni components.
--install-cilium-cni Flag to install Cilium CNI Components.
DEFAULT: Don't install cilium cni components.
--install-multus-cni Flag to install Multus CNI Components.
DEFAULT: Don't install multus cni components.
--install-istio Flag to install Istio Service Mesh Components.
DEFAULT: Don't install istio components.
--install-metallb Flag to install Metal LB Components.
DEFAULT: Don't install loadbalancer components.
--install-nginx-ingress Flag to install Ingress Components - can't be used in combination with istio.
DEFAULT: Don't install ingress components.
--install-contour-ingress Flag to install Ingress Components - can't be used in combination with istio.
DEFAULT: Don't install ingress components.
--install-istio-gateway-api Flag to install Istio Service Mesh Gateway API Components.
DEFAULT: Don't install istio components.
--install-contour-gateway-api Flag to install Ingress Components - can't be used in combination with istio.
DEFAULT: Don't install ingress components.
--install-olm Flag to install Operator Lifecyle Manager
DEFAULT: Don't install olm components.
Visit https://operatorhub.io to install available operators
--delete Delete Kind cluster.
Based on the options you choose, the script renders the needed KinD config YAML file and creates the clusters locally in a couple of minutes. To install Istio Service Mesh on KinD you also need the Istio profile which you can find together with the bootstrap script in my GitHub Gists.
Let’s look into how I use KinD and the bootstrap script in Jenkins for continuous integration (CI). I have a pipeline which executes the bootstrap script to create the cluster on my Jenkins agent.
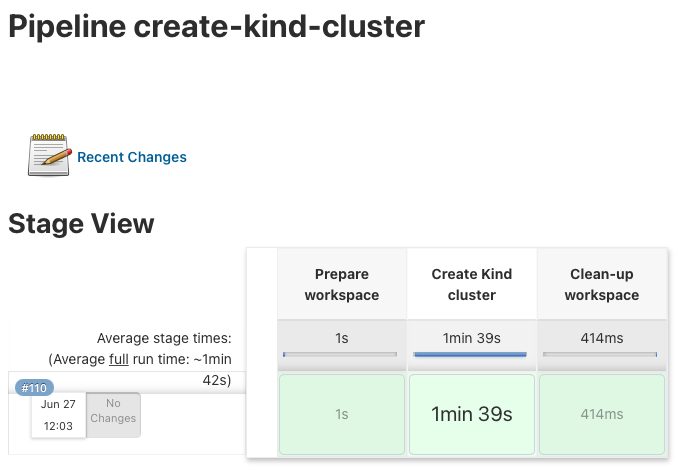
For now I kept the configuration very simple and only need the Nginx Ingress controller in this example:
stages {
stage('Prepare workspace') {
steps {
git credentialsId: 'github-ssh', url: '[email protected]:ab7fb36162f39dbed08f7bd90072a3d2.git'
}
}
stage('Create Kind cluster') {
steps {
sh '''#!/bin/bash
bash ./kind.sh --kubernetes-version v1.21.1 \
--install-nginx-ingress
'''
}
}
stage('Clean-up workspace') {
steps {
sh 'rm -rf *'
}
}
}
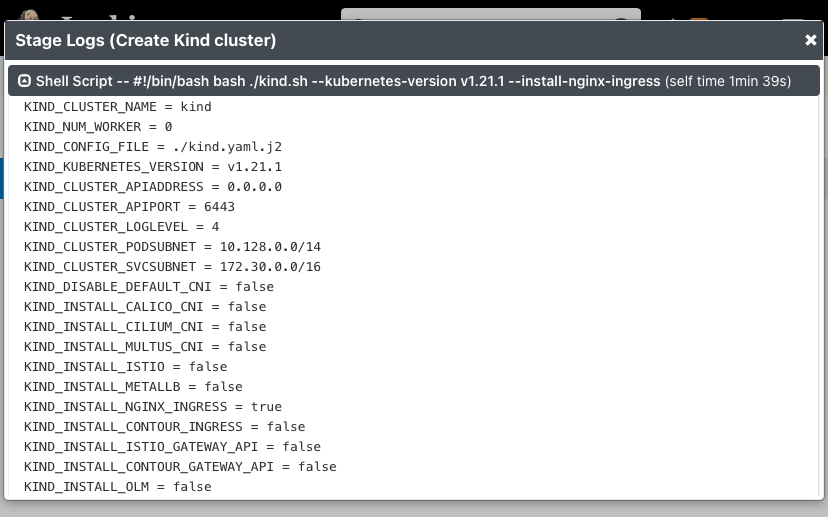
Log output of the script parameters:
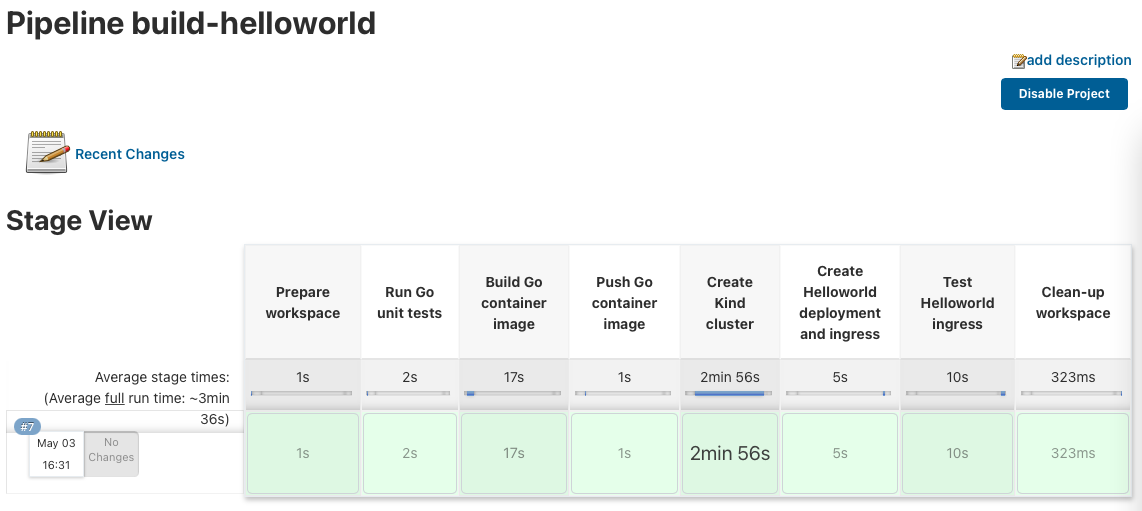
I have written a Go Helloworld application and the Jenkins pipeline which runs the Go unit-tests and builds the container image. It also triggers the build job for the create-kind-cluster pipeline to spin-up the Kubernetes cluster.
...
stage ('Create Kind cluster') {
steps {
build job: 'create-kind-cluster'
}
}
...
It then continues to deploy the newly build Helloworld container image and executes a simple end-to-end ingress test.
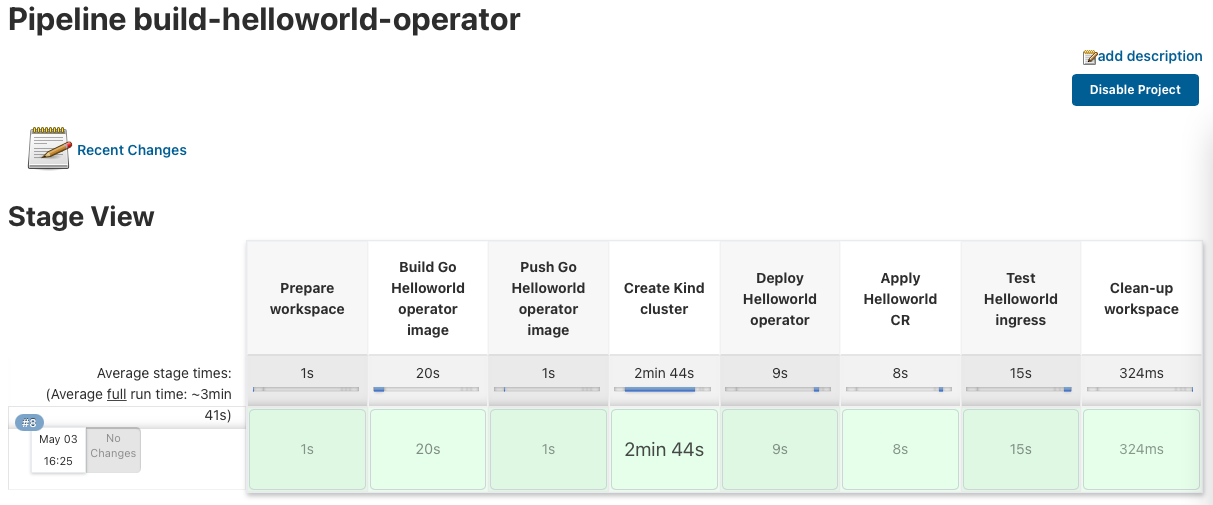
I also use this same example for my Go Helloworld Kubernetes operator build pipeline. It builds the Go operator and again triggers the build job to create the KinD cluster. It then continues to deploy the Helloworld operator and applies the Custom Resources, and finishes with a simple end-to-end ingress test.
I hope this is an interesting and useful article. Visit my GitHub Gists to download the KinD bootstrap script.