RedHat invited me and my colleague Matt to speak at RedHat OpenShift Commons in London about the API driven OpenShift cluster provisioning and management operator called OpenShift Hive. We have been using OpenShift Hive for the past few months to provision and manage the OpenShift 4 estate across multiple environments. Below the video recording of our talk at OpenShift Commons London:
The Hive operator requires to run on a separate Kubernetes cluster to centrally provision and manage the OpenShift 4 clusters. With Hive you can manage hundreds of cluster deployments and configuration with a single operator. There is nothing required on the OpenShift 4 clusters itself, Hive only requires access to the cluster API:
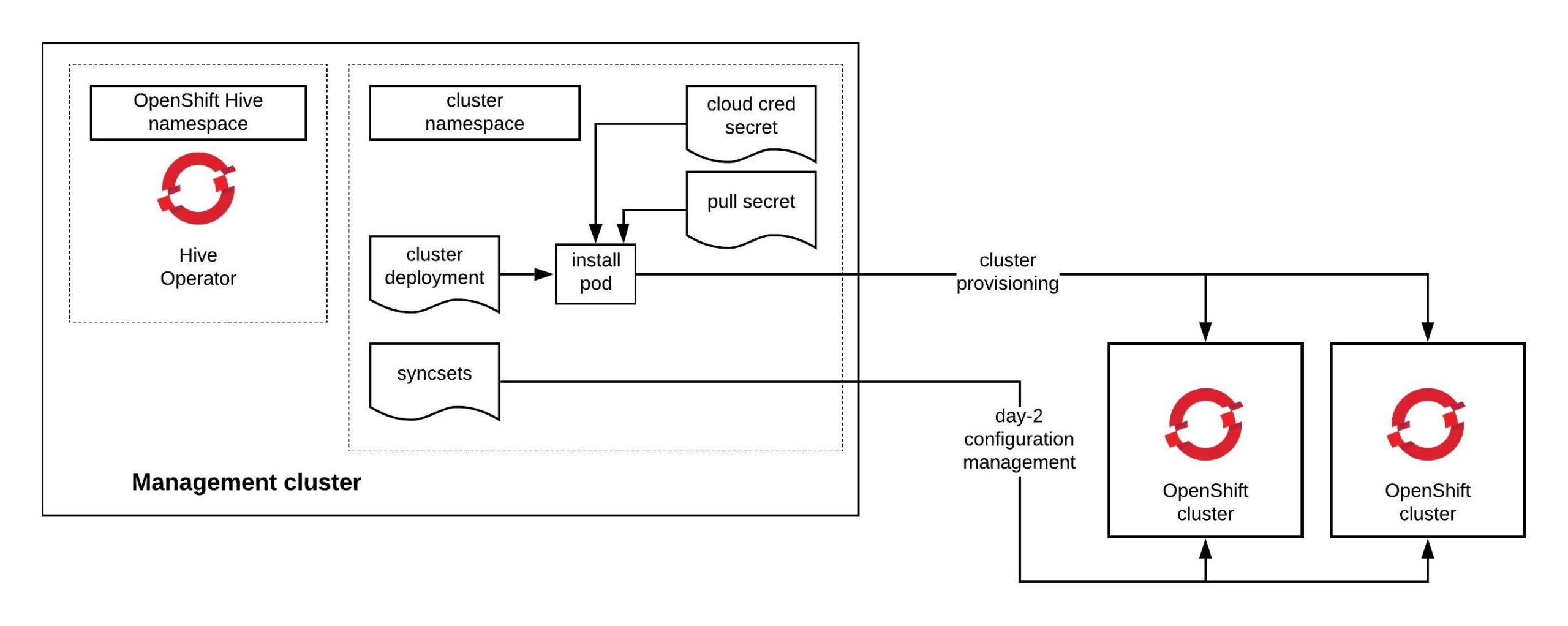
The ClusterDeployment custom resource is the definition for the cluster specs, similar to the openshift-installer install-config where you define cluster specifications, cloud credential and image pull secrets. Below is an example of the ClusterDeployment manifest:
---
apiVersion: hive.openshift.io/v1
kind: ClusterDeployment
metadata:
name: mycluster
namespace: mynamespace
spec:
baseDomain: hive.example.com
clusterName: mycluster
platform:
aws:
credentialsSecretRef:
name: mycluster-aws-creds
region: eu-west-1
provisioning:
imageSetRef:
name: openshift-v4.3.0
installConfigSecretRef:
name: mycluster-install-config
sshPrivateKeySecretRef:
name: mycluster-ssh-key
pullSecretRef:
name: mycluster-pull-secret
The SyncSet custom resource is defining the configuration and is able to regularly reconcile the manifests to keep all clusters synchronised. With SyncSets you can apply resources and patches as you see in the example below:
---
apiVersion: hive.openshift.io/v1
kind: SyncSet
metadata:
name: mygroup
spec:
clusterDeploymentRefs:
- name: ClusterName
resourceApplyMode: Upsert
resources:
- apiVersion: user.openshift.io/v1
kind: Group
metadata:
name: mygroup
users:
- myuser
patches:
- kind: ConfigMap
apiVersion: v1
name: foo
namespace: default
patch: |-
{ "data": { "foo": "new-bar" } }
patchType: merge
secretReferences:
- source:
name: ad-bind-password
namespace: default
target:
name: ad-bind-password
namespace: openshift-config
Depending of the amount of resource and patches you want to apply, a SyncSet can get pretty large and is not very easy to manage. My colleague Matt wrote a SyncSet Generator, please check this Github repository.
In one of my next articles I will go into more detail on how to deploy OpenShift Hive and I’ll provide more examples of how to use ClusterDeployment and SyncSets. In the meantime please check out the OpenShift Hive repository for more details, additionally here are links to the Hive documentation on using Hive and Syncsets.
Read my new article about installing OpenShift Hive.