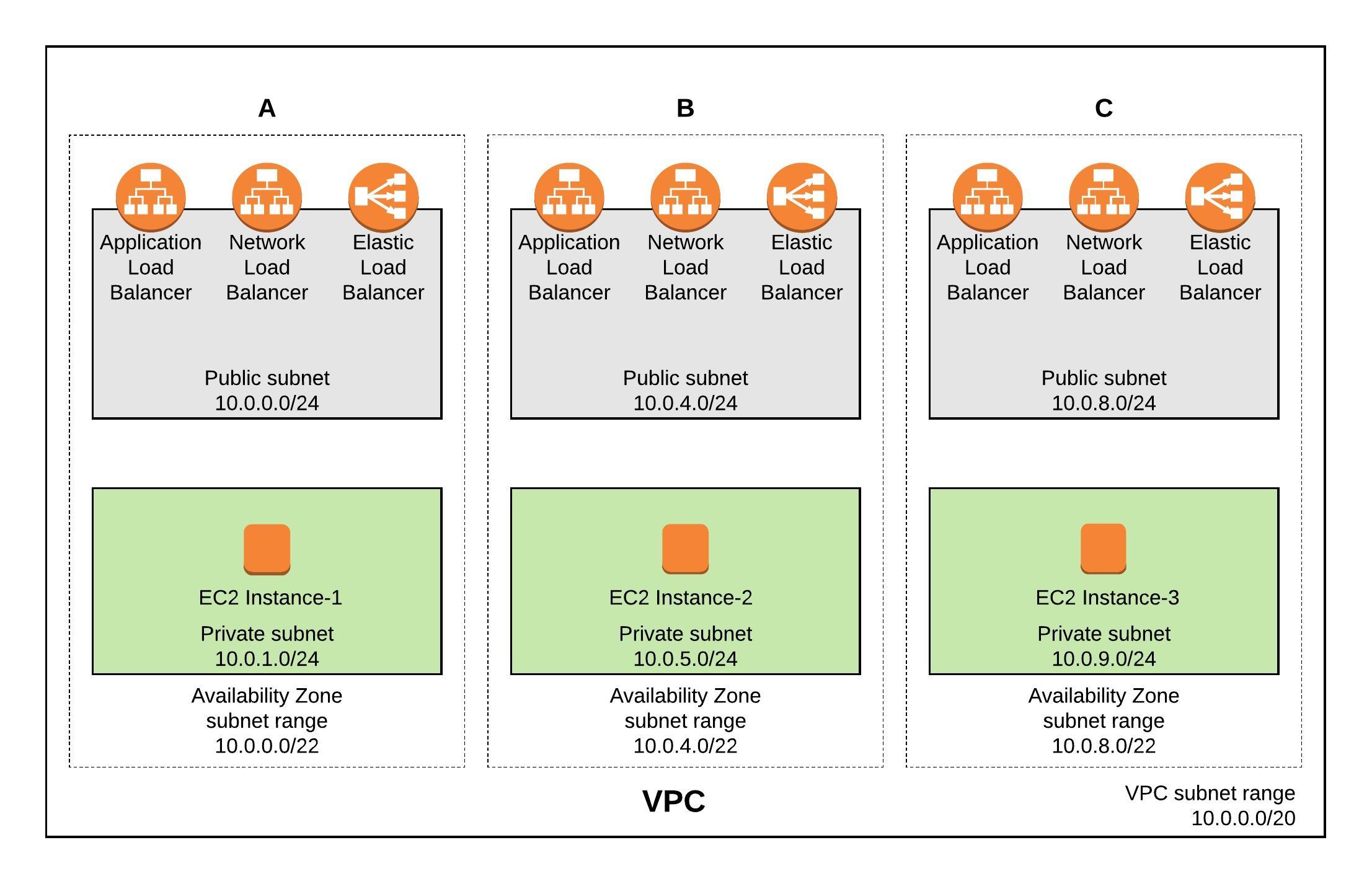
In my first article about the Kubernetes Cluster API and provisioning of AWS workload clusters I mentioned briefly configuring Machine Health Check for the data-place/worker nodes. The Cluster API also supports Machine Health Check for control-plane/master nodes and can automatically remediate any node issues by replacing and provision new instances. The configuration is the same, only the label selector is different for the node type.
Let’s take a look again at the Machine Health Check for data-plane/worker nodes, the selector label is set to nodepool: nodepool-0 to match the label which is configured in the MachineDeployment.
---
apiVersion: cluster.x-k8s.io/v1alpha3
kind: MachineHealthCheck
metadata:
name: cluster-1-node-unhealthy-5m
namespace: k8s
spec:
clusterName: cluster-1
maxUnhealthy: 40%
nodeStartupTimeout: 10m
selector:
matchLabels:
nodepool: nodepool-0
unhealthyConditions:
- type: Ready
status: Unknown
timeout: 300s
- type: Ready
status: "False"
timeout: 300s
To configure Machine Health Check for your control-plane/master add the label cluster.x-k8s.io/control-plane: “” as selector.
---
apiVersion: cluster.x-k8s.io/v1alpha3
kind: MachineHealthCheck
metadata:
name: cluster-1-master-unhealthy-5m
spec:
clusterName: cluster-1
maxUnhealthy: 30%
selector:
matchLabels:
cluster.x-k8s.io/control-plane: ""
unhealthyConditions:
- type: Ready
status: Unknown
timeout: 300s
- type: Ready
status: "False"
timeout: 300s
When both are applied you see the two node groups and the status of available nodes and expected/desired state.
$ kubectl get machinehealthcheck NAME MAXUNHEALTHY EXPECTEDMACHINES CURRENTHEALTHY cluster-1-node-unhealthy-5m 40% 3 3 cluster-1-master-unhealthy-5m 30% 3 3
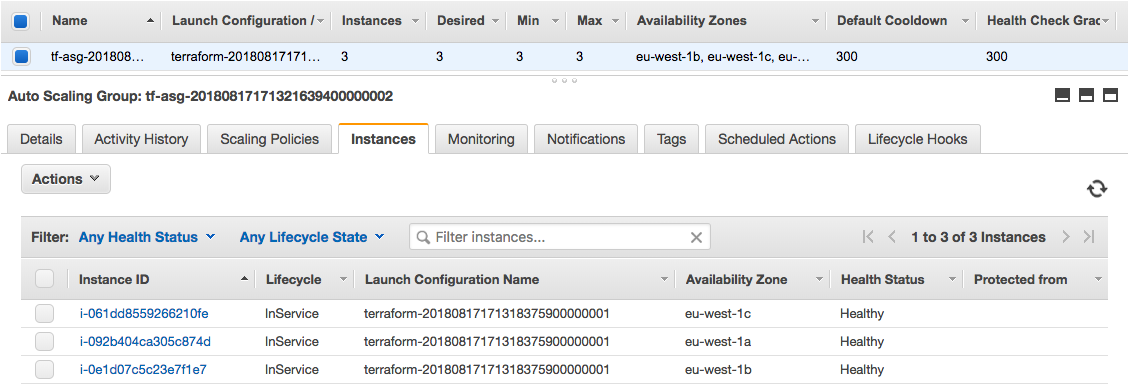
If you terminate one control- and data-plane node, the Machine Health Check identifies these after a couple of minutes and starts the remediation by provisioning new instances to replace the faulty ones. This takes around 5 to 10 min and your cluster is back into the desired state. The management cluster automatically repaired the workload cluster without manual intervention.
$ kubectl get machinehealthcheck NAME MAXUNHEALTHY EXPECTEDMACHINES CURRENTHEALTHY cluster-1-node-unhealthy-5m 40% 3 2 cluster-1-master-unhealthy-5m 30% 3 2
More information about Machine Health Check you can find in the Cluster API documentation.
However, a few ago, I didn’t test running the data-plane/worker nodes on AWS EC2 spot instances which is also supported option in the AWSMachineTemplate. Spot instances for control-plane nodes are not supported and don’t make sense because you need the master nodes available at all time.
Using spot instances can reduce the cost of running your workload cluster and you can see a cost saving of up to 60% – 70% compared to the on-demand price. Although AWS can reclaim these instance by terminating your spot instance at any point in time, they are reliable enough in combination with the Cluster API Machine Health Check that you could run production on spot instances with huge cost savings.
To use spot instances simply add the spotMarketOptions to the AWS Machine Template of the data-plane nodes and the Cluster API will automatically issue spot instance requests for these. If you don’t specify the maxPrice and leave this value blank, this will automatically put the on-demand price as max value for the requested instance type. It makes sense to leave this empty because you cannot be outbid if the marketplace of spot instance suddenly changes because of increasing compute demand.
---
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha3
kind: AWSMachineTemplate
metadata:
name: cluster-1-data-plane-0
namespace: k8s
spec:
template:
spec:
iamInstanceProfile: nodes.cluster-api-provider-aws.sigs.k8s.io
instanceType: t3.small
sshKeyName: default
spotMarketOptions:
maxPrice: ""
In the AWS console you see the spot instance requests.
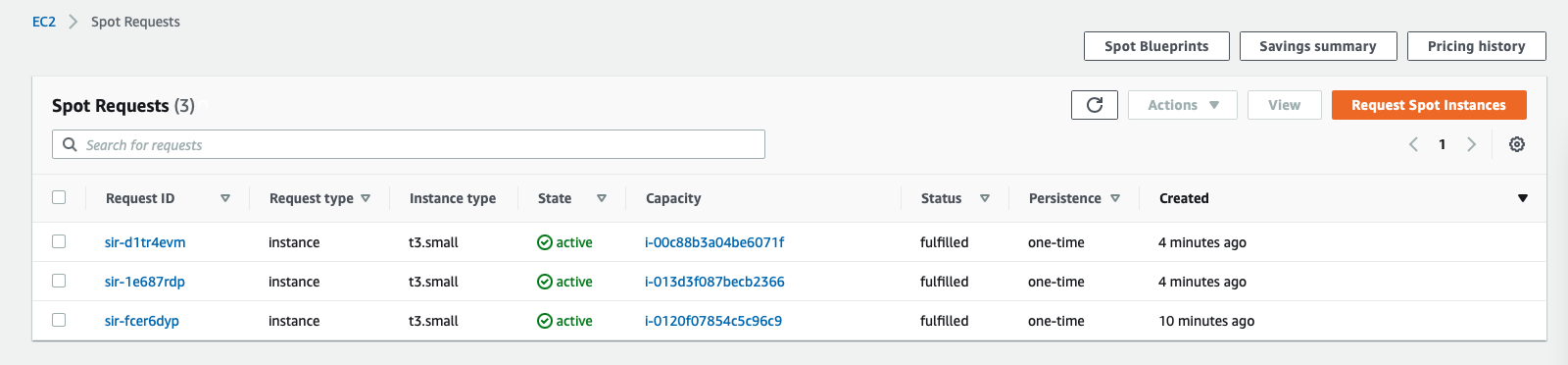
This is great in combination with the Machine Health Check that I explained earlier: if AWS suddenly does reclaim one or multiple of your spot instances, the Machine Health Check will automatically starts to remediate for these missing nodes by requesting new spot instance.