It has become very easy and simple to deploy Kubernetes services using the various cloud offerings like EKS or GKE, after you created your cluster and have the cluster-admin privileges to apply changes as you like. This model is great for development because you can start consuming Kubernetes services right away but this doesn’t work well for production clusters and gets more challenging when running PCI compliant workloads.
I want to explain a bit how to apply a least-privilege principle for Elastic Kubernetes Services (EKS) using the AWS integrated IAM. The diagram below is a simple example showing two IAM roles for admin and reader privileges for AWS resources. On the Kubernetes cluster the IAM roles are bound to the k8s cluster-admin and reader roles. The k8s sudoer role allows to impersonate cluster-admin privileges for cluster readers: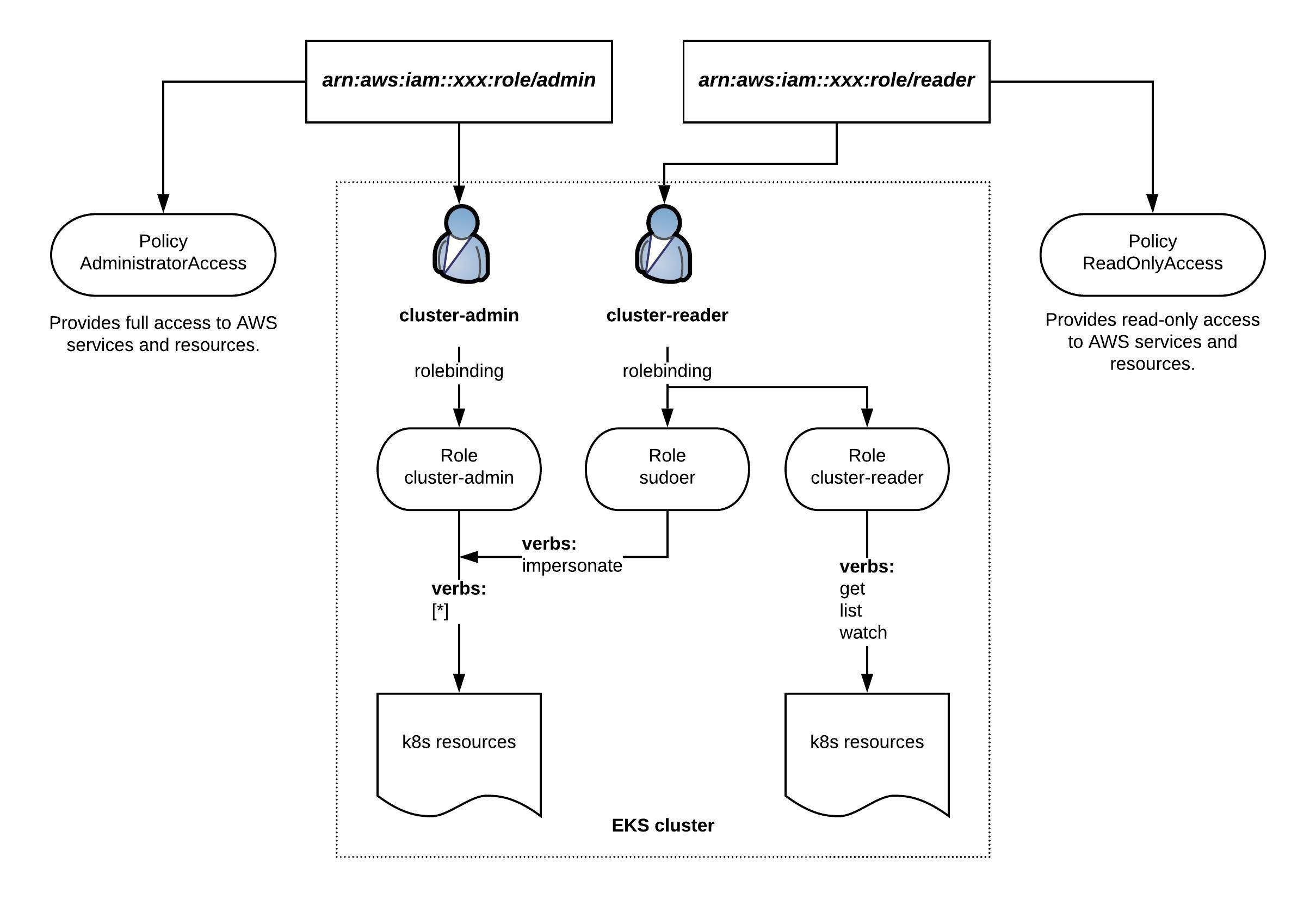
Normally you would add your DevOps team to the IAM reader role. This way the DevOps team has the default read permissions for AWS and Kubernetes resources but they can also elevate Kubernetes permissions to cluster-admin level when required without having full access to the AWS resources.
Let’s look at the EKS aws-auth ConfigMap where you need to define the IAM role mapping for admin and reader to internal Kubernetes groups:
apiVersion: v1
kind: ConfigMap
metadata:
name: aws-auth
namespace: kube-system
data:
mapRoles: |
- rolearn: arn:aws:iam::xxx:role/admin
username: cluster-admin
groups:
- system:masters
- rolearn: arn:aws:iam::xxx:role/reader
username: cluster-reader
groups:
- cluster-reader
- rolearn: arn:aws:iam::555555555555:role/devel-worker-nodes-NodeInstanceRole-74RF4UBDUKL6
username: system:node:{{EC2PrivateDNSName}}
groups:
- system:bootstrappers
- system:nodes
mapUsers: |
[]
The system:masters group is a Kubernetes default role and rolebinding and requires no additional configuration. For the cluster-reader we need to apply a ClusterRole and a ClusterRoleBinding:
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: cluster-reader rules: - apiGroups: - "" resources: - componentstatuses - nodes - nodes/status - persistentvolumeclaims/status - persistentvolumes - persistentvolumes/status - pods/binding - pods/eviction - podtemplates - securitycontextconstraints - services/status verbs: - get - list - watch - apiGroups: - admissionregistration.k8s.io resources: - mutatingwebhookconfigurations - validatingwebhookconfigurations verbs: - get - list - watch - apiGroups: - apps resources: - controllerrevisions - daemonsets/status - deployments/status - replicasets/status - statefulsets/status verbs: - get - list - watch - apiGroups: - apiextensions.k8s.io resources: - customresourcedefinitions - customresourcedefinitions/status verbs: - get - list - watch - apiGroups: - apiregistration.k8s.io resources: - apiservices - apiservices/status verbs: - get - list - watch - apiGroups: - autoscaling resources: - horizontalpodautoscalers/status verbs: - get - list - watch - apiGroups: - batch resources: - cronjobs/status - jobs/status verbs: - get - list - watch - apiGroups: - coordination.k8s.io resources: - leases verbs: - get - list - watch - apiGroups: - extensions resources: - daemonsets/status - deployments/status - horizontalpodautoscalers - horizontalpodautoscalers/status - ingresses/status - jobs - jobs/status - podsecuritypolicies - replicasets/status - replicationcontrollers - storageclasses - thirdpartyresources verbs: - get - list - watch - apiGroups: - events.k8s.io resources: - events verbs: - get - list - watch - apiGroups: - policy resources: - poddisruptionbudgets/status - podsecuritypolicies verbs: - get - list - watch - apiGroups: - rbac.authorization.k8s.io resources: - clusterrolebindings - clusterroles - rolebindings - roles verbs: - get - list - watch - apiGroups: - settings.k8s.io resources: - podpresets verbs: - get - list - watch - apiGroups: - storage.k8s.io resources: - storageclasses - volumeattachments - volumeattachments/status verbs: - get - list - watch - apiGroups: - scheduling.k8s.io resources: - priorityclasses verbs: - get - list - watch - apiGroups: - certificates.k8s.io resources: - certificatesigningrequests - certificatesigningrequests/approval - certificatesigningrequests/status verbs: - get - list - watch - apiGroups: - authorization.k8s.io resources: - localsubjectaccessreviews - selfsubjectaccessreviews - selfsubjectrulesreviews - subjectaccessreviews verbs: - create - apiGroups: - authentication.k8s.io resources: - tokenreviews verbs: - create - apiGroups: - "" resources: - podsecuritypolicyreviews - podsecuritypolicyselfsubjectreviews - podsecuritypolicysubjectreviews verbs: - create - apiGroups: - "" resources: - nodes/metrics - nodes/spec verbs: - get - apiGroups: - "" resources: - nodes/stats verbs: - create - get - nonResourceURLs: - '*' verbs: - get - apiGroups: - networking.k8s.io resources: - ingresses/status verbs: - get - apiGroups: - networking.k8s.io resources: - ingresses/status verbs: - list - apiGroups: - networking.k8s.io resources: - ingresses/status verbs: - watch - apiGroups: - node.k8s.io resources: - runtimeclasses verbs: - get - apiGroups: - node.k8s.io resources: - runtimeclasses verbs: - list - apiGroups: - node.k8s.io resources: - runtimeclasses verbs: - watch - apiGroups: - storage.k8s.io resources: - csidrivers verbs: - get - apiGroups: - storage.k8s.io resources: - csidrivers verbs: - list - apiGroups: - storage.k8s.io resources: - csidrivers verbs: - watch - apiGroups: - storage.k8s.io resources: - csinodes verbs: - get - apiGroups: - storage.k8s.io resources: - csinodes verbs: - list - apiGroups: - storage.k8s.io resources: - csinodes verbs: - watch - apiGroups: - operators.coreos.com resources: - clusterserviceversions - catalogsources - installplans - subscriptions - operatorgroups verbs: - get - list - watch - apiGroups: - packages.operators.coreos.com resources: - packagemanifests - packagemanifests/icon verbs: - get - list - watch - apiGroups: - packages.operators.coreos.com resources: - packagemanifests verbs: - get - list - watch - apiGroups: - "" resources: - namespaces verbs: - get - apiGroups: - "" resources: - configmaps - endpoints - persistentvolumeclaims - pods - replicationcontrollers - replicationcontrollers/scale - serviceaccounts - services verbs: - get - list - watch - apiGroups: - "" resources: - bindings - events - limitranges - namespaces/status - pods/log - pods/status - replicationcontrollers/status - resourcequotas - resourcequotas/status verbs: - get - list - watch - apiGroups: - "" resources: - namespaces verbs: - get - list - watch - apiGroups: - apps resources: - controllerrevisions - daemonsets - deployments - deployments/scale - replicasets - replicasets/scale - statefulsets - statefulsets/scale verbs: - get - list - watch - apiGroups: - autoscaling resources: - horizontalpodautoscalers verbs: - get - list - watch - apiGroups: - batch resources: - cronjobs - jobs verbs: - get - list - watch - apiGroups: - extensions resources: - daemonsets - deployments - deployments/scale - ingresses - networkpolicies - replicasets - replicasets/scale - replicationcontrollers/scale verbs: - get - list - watch - apiGroups: - policy resources: - poddisruptionbudgets verbs: - get - list - watch - apiGroups: - networking.k8s.io resources: - networkpolicies verbs: - get - list - watch - apiGroups: - networking.k8s.io resources: - ingresses verbs: - get - apiGroups: - networking.k8s.io resources: - ingresses verbs: - list - apiGroups: - networking.k8s.io resources: - ingresses verbs: - watch - apiGroups: - metrics.k8s.io resources: - pods verbs: - get - list - watch - apiGroups: - "" resources: - resourcequotausages verbs: - get - list - watch
After you created the ClusterRole you need to create the ClusterRoleBinding:
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: cluster-reader roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-reader subjects: - apiGroup: rbac.authorization.k8s.io kind: Group name: cluster-reader
To give a cluster-reader impersonate permissions you need to create the sudoer ClusterRole with the right to impersonate system:admin:
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: sudoer rules: - apiGroups: - "" resourceNames: - system:admin resources: - systemusers - users verbs: - impersonate - apiGroups: - "" resourceNames: - system:masters resources: - groups - systemgroups verbs: - impersonate
Create the ClusterRoleBinding:
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: sudoer roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: sudoer subjects: - apiGroup: rbac.authorization.k8s.io kind: Group name: cluster-reader
For a cluster-reader to impersonate and get cluster-admin privileges you use the following kubectl options –as-group and –as:
kubectl get nodes --as-group system:masters --as system:admin
You want to restrict the membership of the IAM admin role as much as possible as everyone should only use the read permissions to not accidentally delete Kubernetes or AWS resources.
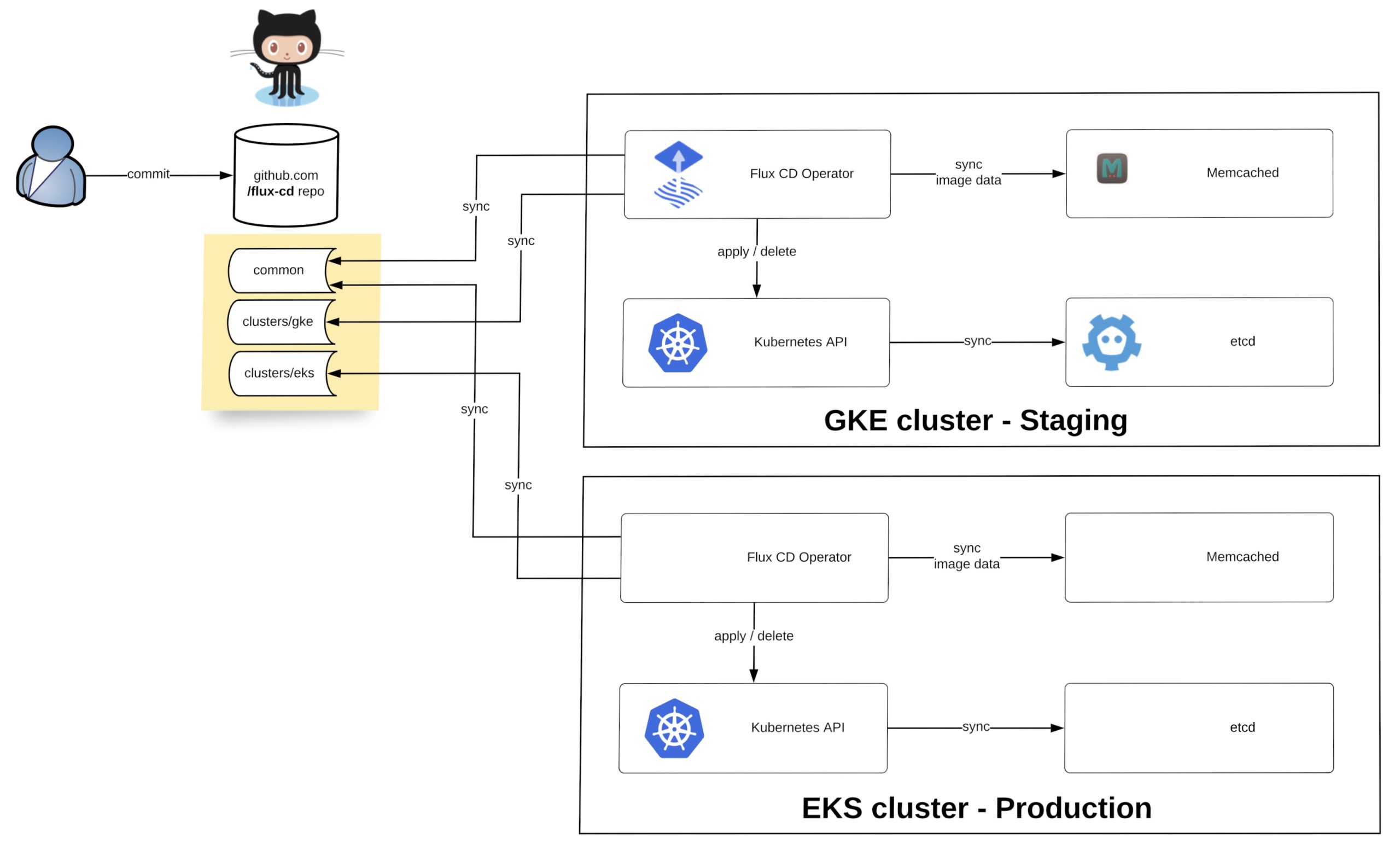
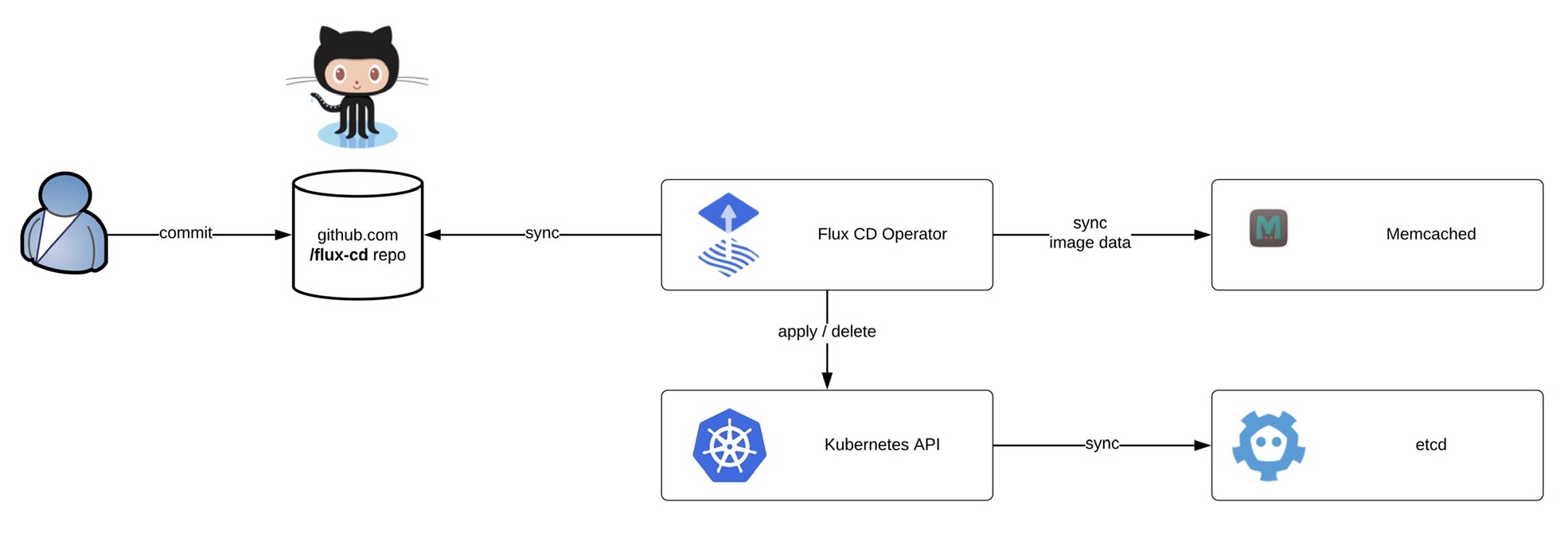 Before we start deploying the operator we need to install the fluxctl command-line utility and create the namespace:
Before we start deploying the operator we need to install the fluxctl command-line utility and create the namespace: Now you are ready to synchronise the Flux operator with the repository. By default Flux automatically synchronises every 5 minutes to apply configuration changes:
Now you are ready to synchronise the Flux operator with the repository. By default Flux automatically synchronises every 5 minutes to apply configuration changes: